在上一篇BLOG中,我们对ODBC的配置和使用方法进行了保姆级教学。在这篇BLOG中,就让我们运用ODBC的知识进行简单的实战吧。
任务一
任务内容
给定一个字符串作为关键字 $s$,我们认为一个关系是满足条件的是说这个关系中存在一个类型是字符串的属性 $S$,使得这个关键字 $s$ 是这个属性 $S$ 的一个子串,也就是说 $S$ 是形如 $\dots s \dots$ 的一个字符串,这里不考虑大小写。现在要输出所有满足条件的关系,要求使用 $like$ 子句动态创建 $SQL$ 查询以实现此功能。
举个例子,加入对于关系:
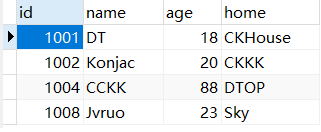
我们设定关键字 $s$ 为 $CK$,那么结果就会输出:
1001 DT 18 CKHouse
1002 Konjac 20 CKKK
1004 CCKK 88 DTOP这是因为,第一行中的 $home$ 属性为 $CKHouse$ 包含 $CK$, 第二行的 $home$ 属性为 $CKKK$ 也包含 $CK$,第三行的 $name$ 属性为 $CCKK$ 还是包含 $CK$。所以我们要输出这三行关系作为答案。
解决思路
初步思想
首先我们先想想,如果单纯使用 $SQL$ 语言,如何实现在忽略大小写的情况下判断关键字 $s$ 是这个属性 $S$ 的一个子串呢?这个其实在 $SQL$ 中非常简单。由于 $SQL$ 本身就是忽略大小写的,所以我们只要聚焦于判断关键字 $s$ 是否是这个属性 $S$ 的子串。这个在 $SQL$ 中也有简单的写法,在 $SQL$ 中,我们可以使用 $like$ 子句,在 $like$ 子句中 $\%$ 可用于定义通配符(模式中缺少的字母),所以假如关键字 $s = CK$,那么 $\%CK\%$ 就可以用来表示包含 $CK$ 的字符串也就是 $CK$ 为其子串的字符串。所以我们的查询就是:
SELECT *
FROM student
WHERE name LIKE "%CK%" OR home LIKE "%CK%"所以最简单的,我们可以定义以下 $SQL$ 查询语句的准备和执行,我们只要在每次运行前修改我们关键字的具体内容就可以了:
//SQL查询语句
SQLTCHAR sql[] = _T("SELECT * FROM student WHERE name like %关键字% OR home like %关键字%");
ret = SQLPrepare(hStmt, sql, SQL_NTS);
check(ret, _T("准备SQL语句"), hEnv, hDbc, hStmt);
ret = SQLExecute(hStmt);
check(ret, _T("执行SQL语句"), hEnv, hDbc, hStmt);更进一步
但更进一步,任务要求我们使用 $like$ 子句动态创建 $SQL$ 查询以实现此功能,要实现这个功能,我们就离不开 $ODBC$ 中 $SQL$ 语句的动态绑定参数,我们在上次的实验报告中我们就重点介绍过这种绑定方法。我们首先在 $SQL$ 查询语句的定义中用 $?$ 先缺省我们要查询的关键字,然后我们通过键盘交互读入用户想要查询的关键字,通过字符串处理将其处理成 $\%关键字\%$ 的形式通过绑定 $SQL$ 语句的参数绑定到之前缺省的 $?$ 上面,最后执行就可以了。所以我们这一部分的代码如下:
//SQL查询语句
SQLTCHAR sql[] = _T("SELECT * FROM student WHERE name LIKE ? OR home LIKE ?");
ret = SQLPrepare(hStmt, sql, SQL_NTS);
check(ret, _T("准备SQL语句"), hEnv, hDbc, hStmt);
//复杂版本绑定SQL语句的参数
SQLLEN len = SQL_NTS;
char temp[50] = { 0 };
TCHAR s[50] = { 0 };
SQLTCHAR parameter[50];
//读入约束的关键字s,并变成 %s% 的形式
wcout << _T("请输入约束的关键字:");
cin >> temp;
int lenth = strlen(temp);
Char2TCHAR(temp, s);
parameter[0] = '%';
for (int i = 1; i <= lenth; i++) parameter[i] = s[i - 1];
parameter[lenth + 1] = '%';
parameter[lenth + 2] = '\0';
//绑定SQL语句的参数
ret = SQLBindParameter(hStmt, 1, SQL_PARAM_INPUT, SQL_C_WCHAR, SQL_WVARCHAR, 50, 0, (SQLPOINTER)parameter, 0, &len);
check(ret, _T("绑定姓名参数"), hEnv, hDbc, hStmt);
ret = SQLBindParameter(hStmt, 2, SQL_PARAM_INPUT, SQL_C_WCHAR, SQL_WVARCHAR, 50, 0, (SQLPOINTER)parameter, 0, &len);
check(ret, _T("绑定住址参数"), hEnv, hDbc, hStmt);
//执行SQL语句
ret = SQLExecute(hStmt);
check(ret, _T("执行SQL语句"), hEnv, hDbc, hStmt);代码实现
我们加上上一次实验报告中的常规 $ODBC$ 模板和 $select$ 的输出,就得到了我们这个任务的完整代码:
#include <iostream>
//ODBC用到的头文件
#include <windows.h>
#include <sql.h>
#include <sqlext.h>
#include <sqltypes.h>
#include <tchar.h>
#include <vector>
using namespace std;
void check(SQLRETURN ret, wstring type, SQLHENV hEnv, SQLHDBC hDbc, SQLHSTMT hStmt) {
if (ret == SQL_ERROR) {
wcout << type << _T("失败!") << endl;
//获取错误信息
SQLTCHAR state[128] = { 0 };
SQLTCHAR msg[128] = { 0 };
SQLRETURN ret = SQLError(hEnv, hDbc, hStmt, state, NULL, msg, sizeof(msg), NULL);
wcout << state << " " << msg << endl;
exit(-1);
}
return;
}
//让char类型字符串转换成TCHAR类型字符串
void Char2TCHAR(const char* _char, TCHAR* tchar)
{
int iLength;
iLength = MultiByteToWideChar(CP_ACP, 0, _char, strlen(_char) + 1, NULL, 0);
MultiByteToWideChar(CP_ACP, 0, _char, strlen(_char) + 1, tchar, iLength);
return;
}
int main()
{
//设置为中文兼容unicode
_wsetlocale(LC_ALL, L"chs");
//声明环境句柄
SQLHENV hEnv = NULL;
//声明连接句柄
SQLHDBC hDbc = NULL;
//声明语句句柄
SQLHSTMT hStmt = NULL;
//声明返回值
SQLRETURN ret;
//分配环境句柄
ret = SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &hEnv);
check(ret, _T("分配环境句柄"), hEnv, hDbc, hStmt);
//设定ODBC版本
ret = SQLSetEnvAttr(hEnv, SQL_ATTR_ODBC_VERSION, (SQLPOINTER)SQL_OV_ODBC3, 0);
check(ret, _T("ODBC版本设置"), hEnv, hDbc, hStmt);
//分配数据库连接句柄
ret = SQLAllocHandle(SQL_HANDLE_DBC, hEnv, &hDbc);
check(ret, _T("分配连接句柄"), hEnv, hDbc, hStmt);
//根据DSN连接数据库,SQL_NTS为自动计算前面字符串长度
ret = SQLConnect(hDbc, (SQLTCHAR*)_T("SQLServerODBC"), SQL_NTS, (SQLTCHAR*)_T("Jvruo"), SQL_NTS, (SQLTCHAR*)_T("Jvruo233"), SQL_NTS);
check(ret, _T("连接数据库"), hEnv, hDbc, hStmt);
wcout << _T("连接数据库成功!") << endl;
//=========================================================================================================
//查询数据1
//分配语句句柄
hStmt = NULL;
ret = SQLAllocHandle(SQL_HANDLE_STMT, hDbc, &hStmt);
check(ret, _T("分配语句句柄"), hEnv, hDbc, hStmt);
//SQL查询语句
SQLTCHAR sql[] = _T("SELECT * FROM student WHERE name LIKE ? OR home LIKE ?");
ret = SQLPrepare(hStmt, sql, SQL_NTS);
check(ret, _T("准备SQL语句"), hEnv, hDbc, hStmt);
//复杂版本绑定SQL语句的参数
SQLLEN len = SQL_NTS;
char temp[50] = { 0 };
TCHAR s[50] = { 0 };
SQLTCHAR parameter[50];
//读入约束的关键字s,并变成 %s% 的形式
wcout << _T("请输入约束的关键字:");
cin >> temp;
int lenth = strlen(temp);
Char2TCHAR(temp, s);
parameter[0] = '%';
for (int i = 1; i <= lenth; i++) parameter[i] = s[i - 1];
parameter[lenth + 1] = '%';
parameter[lenth + 2] = '\0';
//绑定SQL语句的参数
ret = SQLBindParameter(hStmt, 1, SQL_PARAM_INPUT, SQL_C_WCHAR, SQL_WVARCHAR, 50, 0, (SQLPOINTER)parameter, 0, &len);
check(ret, _T("绑定姓名参数"), hEnv, hDbc, hStmt);
ret = SQLBindParameter(hStmt, 2, SQL_PARAM_INPUT, SQL_C_WCHAR, SQL_WVARCHAR, 50, 0, (SQLPOINTER)parameter, 0, &len);
check(ret, _T("绑定住址参数"), hEnv, hDbc, hStmt);
//执行SQL语句
ret = SQLExecute(hStmt);
check(ret, _T("执行SQL语句"), hEnv, hDbc, hStmt);
//查询之后,所有数据放到了一块缓冲区,我们需要把他分离出来
int id = 0;
TCHAR name[50] = { 0 };
short age = 0;
TCHAR home[50] = { 0 };
//绑定字段
len = SQL_NTS;
SQLBindCol(hStmt, 1, SQL_C_LONG, &id, sizeof(id), 0);
SQLBindCol(hStmt, 2, SQL_C_WCHAR, name, sizeof(name), &len);
SQLBindCol(hStmt, 3, SQL_C_SHORT, &age, sizeof(age), 0);
SQLBindCol(hStmt, 4, SQL_C_WCHAR, home, sizeof(home), &len);
//逐行遍历,获取数据
ret = SQLFetch(hStmt);
while (ret != SQL_NO_DATA)
{
wcout << id << "\t" << name << "\t" << age << "\t" << home << endl;
//每次清除一下上行的旧数据,保证下次获取的数据干净
id = 0;
ZeroMemory(name, sizeof(name));
age = 0;
//获取下一行缓冲区的数据填充到id,name,age
ret = SQLFetch(hStmt);
}
SQLLEN n = 0;
ret = SQLRowCount(hStmt, &n);//查询被影响的行数(适用于SELECT ,INSERT,UPDATE,DELETE操作)
check(ret, _T("查询询问行数"), hEnv, hDbc, hStmt);
wcout << _T("查询 ") << n << _T(" 行数据成功!") << endl;
//=========================================================================================================
//释放语句句柄
if (hStmt) {
SQLFreeHandle(SQL_HANDLE_STMT, hStmt);
}
//释放连接句柄
if (hDbc) {
SQLDisconnect(hDbc);
SQLFreeHandle(SQL_HANDLE_DBC, hDbc);
}
//释放环境句柄
if (hEnv) {
SQLFreeHandle(SQL_HANDLE_ENV, hEnv);
}
wcout << _T("断开数据库连接!") << endl;
return 0;
}实验结果
我们可以看到,对于我们上面展示的数据库内容,不论查询的是 $ck$ 还是 $dT$,我们的代码都能成功访问数据库,筛选出我们满足条件的关系返回回来:
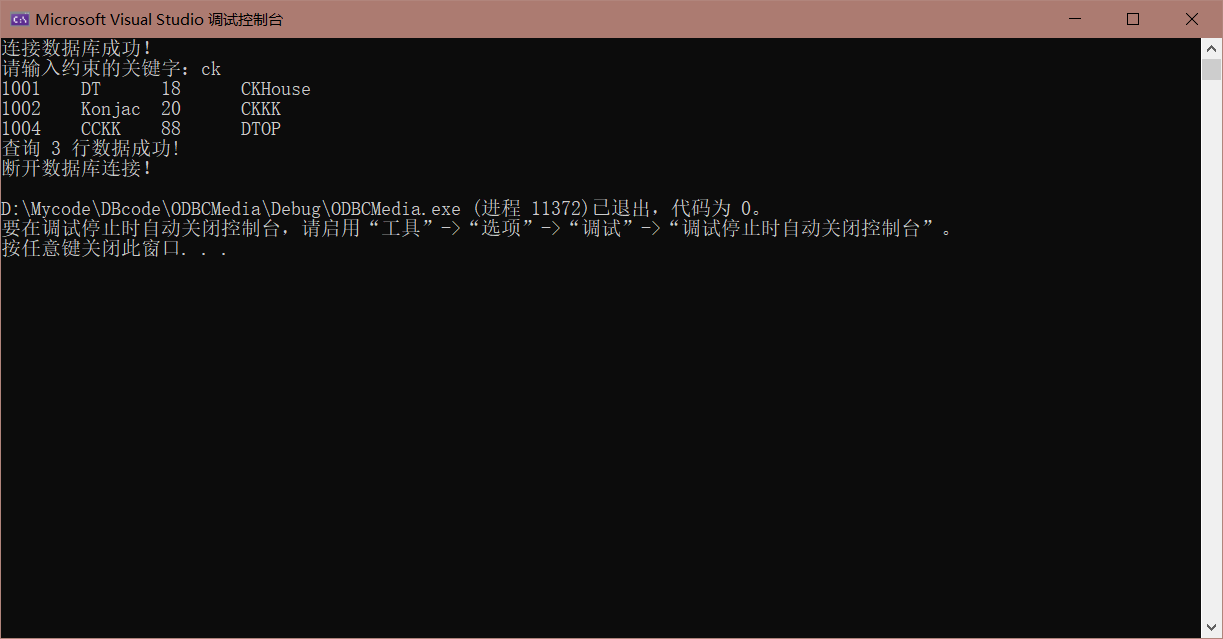
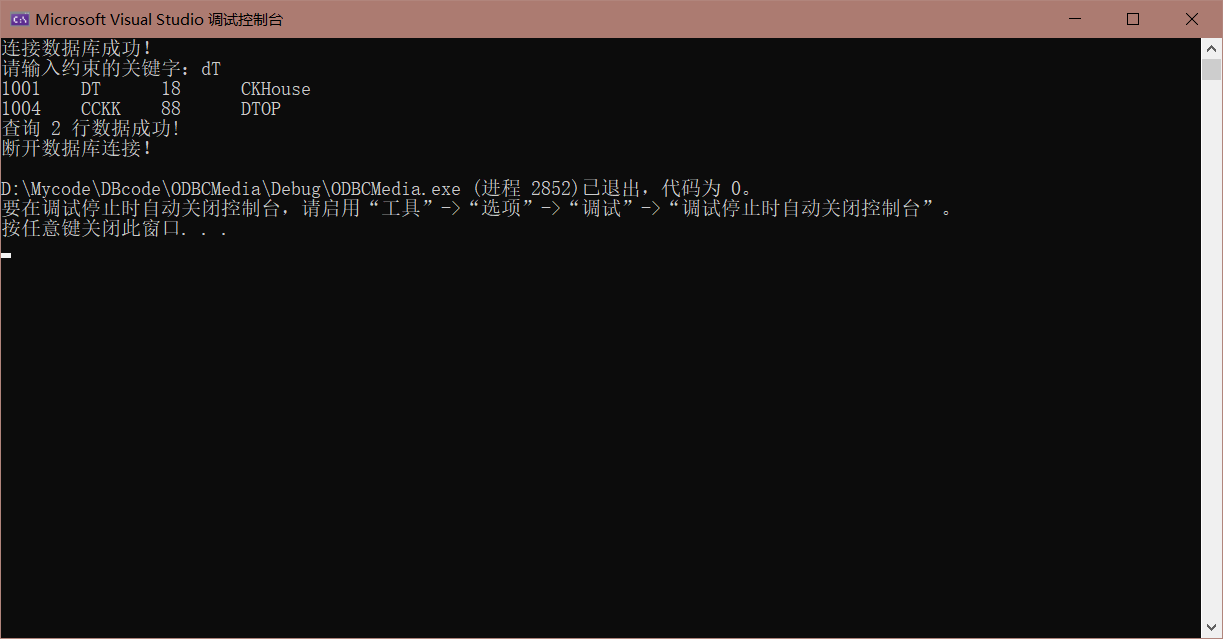
任务二
任务内容
任务二是任务一的升级版。
给定若干个字符串作为关键字集合 $s_i$,我们认为一个关系是满足条件的是说对于关键字集合中的每个关键字 $s_i$. 这个关系中至少存在一个类型是字符串的属性 $S$,使得这个关键字 $s_i$ 是这个属性 $S$ 的一个子串,也就是说 $S$ 是形如 $\dots s_i \dots$ 的一个字符串,这里仍然不考虑大小写。现在要输出所有满足条件的关系。
举个例子,加入对于关系:
我们设定关键集合字 $s_i$ 为 $(CK, DT)$,那么结果就会输出:
1001 DT 18 CKHOUSE
1004 CCKK 88 DTOP这是因为,第一行中的 $home$ 属性为 $CKHouse$ 包含 $CK$,$name$ 属性为 $DT$ 包含 $DT$;第二行的 $name$ 属性为 $CCKK$ 包含 $CK$,$home$ 属性为 $DTOP$ 包含 $DT$。所以我们要输出这两行关系作为答案。
解决思路
我们发现任务二相较于任务一,其难度有了质的飞跃,由于我们的关键字个数和关键之的具体内容是不确定的,所以我们很难用单纯的 $SQL$ 语句表示出我们现如今的约束,这就导致单纯使用 $SQL$ 语句加上参数绑定的方式已经非常吃力了。这就体现出我们 $ODBC$ 的含金量了,$SQL$ 处理不了的复杂问题,我们就丢到 $C++$ 里来处理嘛。
沿着这个思路,我们的想法两步走—读取表格数据和处理读取数据。
读取表格数据
读取表格数据,就是要把我们要查询的表格的所有数据存储到一个结构体里,方便我们进一步使用 $C++$ 对表格中的数据进行剔除和处理。所以第一步我们要根据我们表格定义的属性定义我们存储的结构体:
//定义存储
struct node {
int id = 0;
TCHAR name[50] = { 0 };
short age = 0;
TCHAR home[50] = { 0 };
}member[1100];接下来,我们还是照旧定义我们的 $SQL$ 查询语句 为 $SELECT \space * \space FROM \space student$ 代表选出 $student$ 表中的所有信息,然后我们照常准备和执行 $SQL$ 语句,只是在后面原有的输出数据的部分我们变成了把查询到的数据放进我们的结构体里。所以我们这一部分的代码如下:
//SQL查询语句
SQLTCHAR sql[] = _T("SELECT * FROM student");
ret = SQLPrepare(hStmt, sql, SQL_NTS);
check(ret, _T("准备SQL语句"), hEnv, hDbc, hStmt);
//执行SQL语句
ret = SQLExecute(hStmt);
check(ret, _T("执行SQL语句"), hEnv, hDbc, hStmt);
//查询之后,所有数据放到了一块缓冲区,我们需要把他分离出来
int id = 0;
TCHAR name[50] = { 0 };
short age = 0;
TCHAR home[50] = { 0 };
//绑定字段
SQLLEN len = SQL_NTS;
SQLBindCol(hStmt, 1, SQL_C_LONG, &id, sizeof(id), 0);
SQLBindCol(hStmt, 2, SQL_C_WCHAR, name, sizeof(name), &len);
SQLBindCol(hStmt, 3, SQL_C_SHORT, &age, sizeof(age), 0);
SQLBindCol(hStmt, 4, SQL_C_WCHAR, home, sizeof(home), &len);
//逐行遍历,获取数据
ret = SQLFetch(hStmt);
int num = 0;
while (ret != SQL_NO_DATA)
{
num++;
member[num].id = id; member[num].age = age;
memcpy(member[num].name, name, 50);
memcpy(member[num].home, home, 50);
//每次清除一下上行的旧数据,保证下次获取的数据干净
id = 0;
ZeroMemory(name, sizeof(name));
age = 0;
//获取下一行缓冲区的数据填充到id,name,age
ret = SQLFetch(hStmt);
}处理读取数据
在这一部分,我们针对我们上面取出来的数据,我们定义一个 $vis[i]$ 初始化为 $0$ 表示第 $i$ 个关系初始是满足条件的。接下来我们先读入约束的关键字个数,然后对于每个关键字,我们首先用键盘读入该关键字,然后我们依次遍历我们上面读取到的每一条关系去判断我们的关键字是不是这个关系的 $name$ 或者 $home$ 属性的子串。我们以潘多我们当前关键字 $s$ 是不是第 $j$ 条关系的 $name$ 属性 $member[j].name$ 的子串。由于忽略大小写,所以我们首先使用 $_wcsupr(x)$ 函数将我们的字符串 $x$ 都变成大写,然后使用函数 $wcsstr(x, y)$ 寻找 $y$ 在 $x$ 中第一次出现的位置,若返回值是 $NULL$ 则表示 $x$ 中没有出现过 $y$ 也就是 $y$ 不是 $x$ 的子串,所以我们 $s$ 不是 $member[j].name$ 的子串的判断条件就形如 $wcsstr(_wcsupr(member[j].name), _wcsupr(s)) == NULL$,同样地对于 $member[j].home$ 的判断也是如此。如果 $s$ 既不是 $member[j].name$ 的子串也不是 $member[j].home$ 的子串那么第 $j$ 条关系就是不合法的,我们就设 $vis[j] = 1$。在遍历完所有的关键字后,我们输出那些 $vis[i] == 0$ 的第 $i$ 个关系就表示每个关键字都在其中出现过的那些合法的关系。所以我们这一部分的代码如下:
int m = 0;
vector<int> vis(num + 1, 0);
wcout << _T("请输入约束的关键字个数:");
cin >> m;
for (int i = 1; i <= m; i++) {
char temp[50] = { 0 };
TCHAR s[50] = { 0 };
cin >> temp;
Char2TCHAR(temp, s);
for (int j = 1; j <= num; j++) {
if (wcsstr(_wcsupr(member[j].name), _wcsupr(s)) == NULL && wcsstr(_wcsupr(member[j].home), _wcsupr(s)) == NULL) {
vis[j] = 1;
//cout << j << endl;
}
}
}
int ans = 0;
for (int i = 1; i <= num; i++) {
if (vis[i] == 0) {
wcout << member[i].id << "\t" << member[i].name << "\t" << member[i].age << "\t" << member[i].home << endl;
}
}
wcout << _T("查询 ") << ans << _T(" 行数据成功!") << endl;代码实现
我们加上上一次实验报告中的常规 $ODBC$ 模板,就得到了我们这个任务的完整代码:
#include <iostream>
//ODBC用到的头文件
#include <windows.h>
#include <sql.h>
#include <sqlext.h>
#include <sqltypes.h>
#include <tchar.h>
#include <vector>
using namespace std;
//定义存储
struct node {
int id = 0;
TCHAR name[50] = { 0 };
short age = 0;
TCHAR home[50] = { 0 };
}member[1100];
//检测ODBC错误
void check(SQLRETURN ret, wstring type, SQLHENV hEnv, SQLHDBC hDbc, SQLHSTMT hStmt) {
if (ret == SQL_ERROR) {
wcout << type << _T("失败!") << endl;
//获取错误信息
SQLTCHAR state[128] = { 0 };
SQLTCHAR msg[128] = { 0 };
SQLRETURN ret = SQLError(hEnv, hDbc, hStmt, state, NULL, msg, sizeof(msg), NULL);
wcout << state << " " << msg << endl;
exit(-1);
}
return;
}
//让char类型字符串转换成TCHAR类型字符串
void Char2TCHAR(const char* _char, TCHAR* tchar)
{
int iLength;
iLength = MultiByteToWideChar(CP_ACP, 0, _char, strlen(_char) + 1, NULL, 0);
MultiByteToWideChar(CP_ACP, 0, _char, strlen(_char) + 1, tchar, iLength);
return;
}
int main()
{
//设置为中文兼容unicode
_wsetlocale(LC_ALL, L"chs");
//声明环境句柄
SQLHENV hEnv = NULL;
//声明连接句柄
SQLHDBC hDbc = NULL;
//声明语句句柄
SQLHSTMT hStmt = NULL;
//声明返回值
SQLRETURN ret;
//分配环境句柄
ret = SQLAllocHandle(SQL_HANDLE_ENV, SQL_NULL_HANDLE, &hEnv);
check(ret, _T("分配环境句柄"), hEnv, hDbc, hStmt);
//设定ODBC版本
ret = SQLSetEnvAttr(hEnv, SQL_ATTR_ODBC_VERSION, (SQLPOINTER)SQL_OV_ODBC3, 0);
check(ret, _T("ODBC版本设置"), hEnv, hDbc, hStmt);
//分配数据库连接句柄
ret = SQLAllocHandle(SQL_HANDLE_DBC, hEnv, &hDbc);
check(ret, _T("分配连接句柄"), hEnv, hDbc, hStmt);
//根据DSN连接数据库,SQL_NTS为自动计算前面字符串长度
ret = SQLConnect(hDbc, (SQLTCHAR*)_T("SQLServerODBC"), SQL_NTS, (SQLTCHAR*)_T("Jvruo"), SQL_NTS, (SQLTCHAR*)_T("Jvruo233"), SQL_NTS);
check(ret, _T("连接数据库"), hEnv, hDbc, hStmt);
wcout << _T("连接数据库成功!") << endl;
//查询数据2
//分配语句句柄
hStmt = NULL;
ret = SQLAllocHandle(SQL_HANDLE_STMT, hDbc, &hStmt);
check(ret, _T("分配语句句柄"), hEnv, hDbc, hStmt);
//SQL查询语句
SQLTCHAR sql[] = _T("SELECT * FROM student");
ret = SQLPrepare(hStmt, sql, SQL_NTS);
check(ret, _T("准备SQL语句"), hEnv, hDbc, hStmt);
//执行SQL语句
ret = SQLExecute(hStmt);
check(ret, _T("执行SQL语句"), hEnv, hDbc, hStmt);
//查询之后,所有数据放到了一块缓冲区,我们需要把他分离出来
int id = 0;
TCHAR name[50] = { 0 };
short age = 0;
TCHAR home[50] = { 0 };
//绑定字段
SQLLEN len = SQL_NTS;
SQLBindCol(hStmt, 1, SQL_C_LONG, &id, sizeof(id), 0);
SQLBindCol(hStmt, 2, SQL_C_WCHAR, name, sizeof(name), &len);
SQLBindCol(hStmt, 3, SQL_C_SHORT, &age, sizeof(age), 0);
SQLBindCol(hStmt, 4, SQL_C_WCHAR, home, sizeof(home), &len);
//逐行遍历,获取数据
ret = SQLFetch(hStmt);
int num = 0;
while (ret != SQL_NO_DATA)
{
num++;
member[num].id = id; member[num].age = age;
memcpy(member[num].name, name, 50);
memcpy(member[num].home, home, 50);
//每次清除一下上行的旧数据,保证下次获取的数据干净
id = 0;
ZeroMemory(name, sizeof(name));
age = 0;
//获取下一行缓冲区的数据填充到id,name,age
ret = SQLFetch(hStmt);
}
int m = 0;
vector<int> vis(num + 1, 0);
wcout << _T("请输入约束的关键字个数:");
cin >> m;
for (int i = 1; i <= m; i++) {
char temp[50] = { 0 };
TCHAR s[50] = { 0 };
cin >> temp;
Char2TCHAR(temp, s);
for (int j = 1; j <= num; j++) {
if (wcsstr(_wcsupr(member[j].name), _wcsupr(s)) == NULL && wcsstr(_wcsupr(member[j].home), _wcsupr(s)) == NULL) {
vis[j] = 1;
//cout << j << endl;
}
}
}
int ans = 0;
for (int i = 1; i <= num; i++) {
if (vis[i] == 0) {
wcout << member[i].id << "\t" << member[i].name << "\t" << member[i].age << "\t" << member[i].home << endl;
}
}
wcout << _T("查询 ") << ans << _T(" 行数据成功!") << endl;
//=========================================================================================================
//释放语句句柄
if (hStmt) {
SQLFreeHandle(SQL_HANDLE_STMT, hStmt);
}
//释放连接句柄
if (hDbc) {
SQLDisconnect(hDbc);
SQLFreeHandle(SQL_HANDLE_DBC, hDbc);
}
//释放环境句柄
if (hEnv) {
SQLFreeHandle(SQL_HANDLE_ENV, hEnv);
}
wcout << _T("断开数据库连接!") << endl;
return 0;
}实验结果
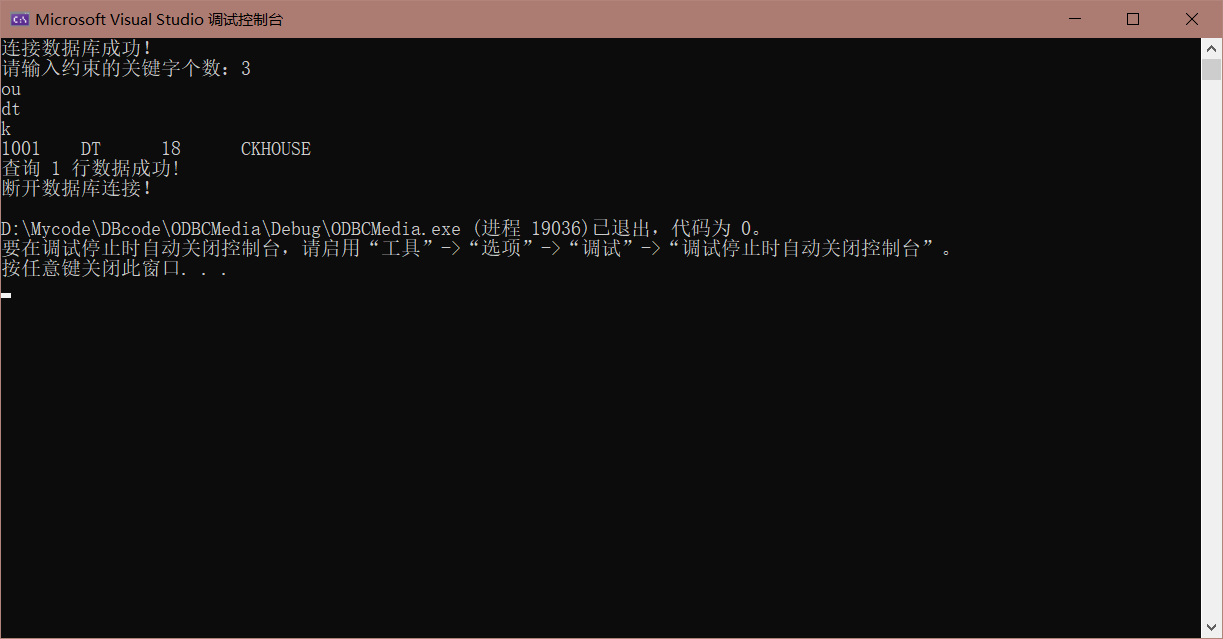
我们还是在上面展示的数据库中的 $student$ 表进行操作。我们查询 $(CK, dT)$ 以及 $(ou, dt, k)$ 都能顺利得到答案:
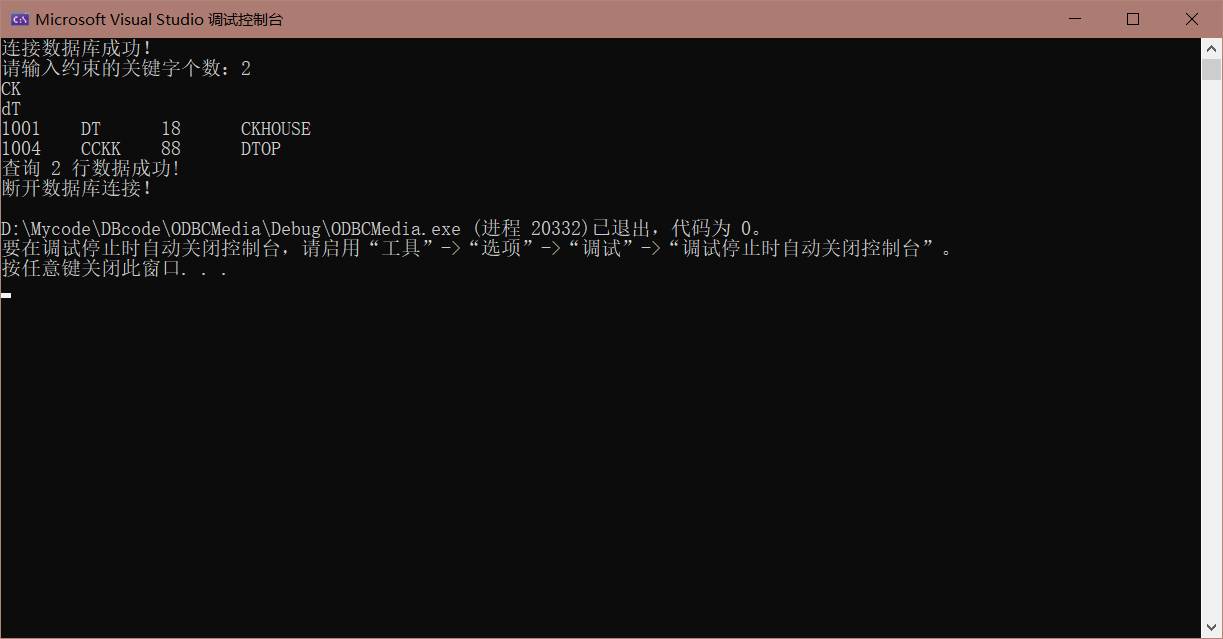
结语
通过这篇BLOG,我们从上一篇BLOG的理论学习作为基础,完成了这一次实践。虽然大体内容都是上一次实验的衍生,但是 $SQL$ 通过 $ODBC$ 使得我们能在 $C++$ 上通过更加灵活的语法和结构完成更加复杂的事情在这次实验体现的淋漓尽致,也确实让我们体会到了 $ODBC$ 是非常有用的。最后希望你喜欢这篇BLOG!

