在这篇BLOG中,我们将继续聚焦大数据机器学习,看看在线学习和并行计算这两种全新的优化手段。
在线学习
在这一部分我们将会一起学习一种新的大规模的机器学习机制叫做在线学习。这种在线学习机制让我们可以模型化问题在拥有连续一波数据或连续的数据流涌进来时从中学习模型。
现如今许多大型网站或者许多大型网络公司都在使用不同版本的在线学习机制算法从大批的涌入又离开网站的用户身上进行学习。特别要提及的是如果我们有一个由连续的用户流引发的连续的数据流,我们能做的是使用一个在线学习机制从数据流中学习用户的偏好,然后使用这些信息来优化一些关于网站的决策。
假定我们有一个提供运输服务的公司,每次服务前用户们都会向我们的网站询问把包裹从A地运到B地的服务的服务价格是多少。比如我们网站回答从上海到广州会收取¥50来运输这个包裹。然后根据我们开给用户的不同价格,用户有时会接受这个运输服务那么这就是个正样本,有时他们会走掉拒绝购买我们的运输服务那么这就是个负样本。假定我们想要一个学习算法来帮助我们优化给用户开出的价格,而且特别的是我们假定找到了一些获取用户特点的方法,比如如果我们知道一些用户的统计信息,它们会获取比如包裹的起始地 以及目的地,他们想把包裹运到哪里去以及我们提供给他们的运送包裹的价格。我们想要做的就是学习在给出的价格下他们将会选择运输包裹的几率。
在已知用户特点和我们开出的价格的前提下,如果我们可以估计出用户选择使用我们的服务的几率,那么我们就可以试着去选择一个优化的价格并寻找一个在盈利的前提下用户会有更大的可能性选择我们的网站的报价。我们能做的就是用逻辑回归或者神经网络或者其他一些类似的算法,但为了简化问题现在我们先来考虑逻辑回归。现在假定我们有一个连续运行的网站以下就是在线学习算法要做的:

我要写下"Repeat forever" 这只是代表着我们的网站将会一直继续保持在线学习,这个网站将要发生的是一个用户偶然访问,然后我们将会得到与其对应的一些(x,y)对,这些(x,y)对是相对应于一个特定的客户或用户的所以特征。其中 x 是指 客户所指定的起始地与目的地以及我们这一次提供给客户的价格,而y则取 1 或 0 取决于客户是否选择使用我们的运输服务。
现在我们一旦获得了这个{x,y}数据对,在线学习算法要做的就是利用刚得到的(x,y)数据对来更新θ。具体来说我们将这样更新我们的参数θ,θj 将会被更新为 θj 减去学习率 α 乘以一个偏导数项。然后我们对j(数据维数)等于0到n重复这个步骤。你也许发现了,对于其他的学习算法我们一般不是写(x,y)而写的是 (x(i),y(i)) 一样的数据对对吧,但在这个在线学习机制中我们实际上丢弃了获取一个固定的数据集这样的概念,取而代之的是我们拥有一个算法,当我们获取一个样本,我们就立刻利用那个样本获取信息学习,然后我们丢弃这个样本并且永远不会再使用它,这就是为什么我们在一个时间点只会处理一个样本的原因。我们从样本中学习再丢弃它,这也就是为什么我们放弃了一种拥有固定的由 i 来作参数的数据集的表示方法。
如果我们真的运行一个大型网站,在这个网站里我们有一个连续的用户流登陆窗口,那么这种在线学习算法是一种非常合理的算法。因为数据本质上是自由的,如果我们有如此多的数据,而数据本质上是无限的,那么或许就真的没必要重复处理一个样本。当然如果我们只有少量的用户,那么我们就不选择像这样的在线学习算法,可能最好是要保存好所有的数据保存在一个固定的数据集里,然后对这个数据集使用某种算法。但是如果我们确实有一个连续的数据流那么一个在线学习机制会非常的有效。
我也必须要提到一个这种在线学习算法会带来的有趣的效果,那就是它可以对正在变化的用户偏好进行调适而且特别的随着时间变化大的经济环境发在慢慢生变化,用户们可能会开始变得对价格更敏感然后不那么愿意支付高的费用;也有可能他们变得对价格不那么敏感然后他们愿意支付更高的价格;又或者各种因素变得对用户的影响更大了。如果我们开始拥有某一种新的类型的用户涌入你的网站,那么这样的在线学习算法也可以根据变化着的用户偏好进行调适,而且从某种程度上可以跟进变化着的用户群体所愿意支付的价格。而且在线学习算法有这样的作用是因为如果我们的用户群变化了,那么参数θ的变化与更新,并且会逐渐调适到我们最新的用户群所应该体现出来的参数。
这里有另一个使用在线学习的例子,这是一个对于产品搜索的应用。在这个应用中我们想要使用一种学习机制来学习如何反馈给用户好的搜索列表。举个例子说假如我们有一个在线卖智能手机的商铺而且我们有一个用户界面可以让用户登陆你的网站并且键入一个搜索条目。例如“安卓 手机 4K分辨率 四摄像头” ,假定我们的商铺中有一百部电话而且出于我们的网站设计,当一个用户键入一个命令,我们会想要找到一个合适的十部不同手机的列表来提供给用户。我们想要做的是拥有一个在线学习机制来帮助我们找到在这100部手机中哪十部手机是我们真正应该反馈给用户的,而且这个返回的列表是对类似这样的用户搜索条目最佳的回。接下来要说的是一种解决问题的思路,我们可以对于每一个手机以及一个给定的用户搜索命令构建一个特征矢量 x ,那么这个特征矢量 x 可能会抓取手机的各种特点,它可能会抓取类似于用户搜索命令与这部电话的类似程度有多高这样的信息。我们获取类似于这个用户搜索命令中有多少个词可以与这部手机的名字相匹配或者这个搜索命令中有多少词与这部手机的描述相匹配,所以特征矢量x获取 手的特点而且 它会获取这部手机与搜索命令的结果在各个方面的匹配程度。我们想要做的就是估测一个概率,这个概率是指用户将会点进某一个特定的手机的链接,因为我们想要给用户展示他们想要买的手机。所以我将定义y等于1时是指用户点击了手机的链接,而y等于0是指用户没有点击链接。然后我们想要做的就是学习到用户将会点击某一个背给出的特定的手机的概率,我们知道的特征X获取了手机的特点以及搜索条目与手机的匹配程度。
如果要给这个问题命一个名,用一种运行这类网站的人们所使用的语言来命名这类学习问题,这类问题其实被称作学习预测的点击率问题,也就是预估点击率CTR。它仅仅代表这学习用户将点击某一个特定的我们提供给他们的链接的概率,而CTR是点击率(Click Through Rate)的简称。然后如果我们能够估计任意一个特定手机的点击率,我们可以做的就是利用这个来给用户展示十个他们最有可能点击的手机。因为从这一百个手机中我们可以计算出 100 部手机中每一部手机的可能的点击率,我们就能选择10部用户最有可能点击的手机。这就是一个非常合理的来决定要展示给用户的十个搜索结果的方法。更明确地说假定每次用户进行一次搜索,我们回馈给用户十个结果,在线学习算法会做的是它会真正地提供给我们十个 (x,y) 数据对,这就给了我们十个数据样本。每当一个用户来到我们网站时就给了我们十个样本,因为对于这十部我们选择要展示给用户的手机中的每一个我们会得到一个特征矢量x,而且对于这10部手机中的任何一个手机我们还会根据用户是否点击得到 y 的取值。那么每次一个用户访问,我们将会得到十个样本(x,y) 数据对,然后利用一个在线学习算法来更新我们的参数。更新过程中会对这十个样本利用梯度下降法,算法结束后我们可以丢弃这些数据了,这就是在线学习算法。
以上就是一个产品搜索问题或者说是一个学习将手机排序的问题。接着我们来快速地看一些其他的例子。其中一个例子是如果我们有一个网站并尝试着来决定我们要给用户展示什么样的特别优惠,这与手机那个例子非常类似;或者我们有一个网站,然后我们想给不同的用户展示不同的新闻文章。那么如果我们有一个新闻抓取网站,我们又可以使用一个类似在线学习的系统来选择他们最有可能点击的新闻展示给用户。而且实际上如果我们有一个协作过滤系统,就可以给我们的在线学习带来更多的特征,这些特征可以整合到逻辑回归的分类器,从而可以尝试着预测对于你可能推荐给用户的 不同产品的点击率。当然我需要说明的是这些问题中的任何一个都可以被归类到标准的拥有一个固定的样本集的机器学习问题中,但在大数据面前我们完全可以使用一个在线学习算法来连续的学习,从这些用户不断产生的数据中来学习。
以上就是在线学习机制,然后就像我们所看到的我们所使用的这个算法与随机梯度下降算法非常类似,唯一的区别的是我们不会使用一个固定的数据集而是会获取一个用户样本,并且从那个样本中学习。在学习完成后丢弃那个样本并继续下去。如果我们对某一种应用有一个连续的数据流使用这样的算法将会事半功倍。当然在线学习还有许多优点就留给你们去慢慢发掘了。
映射约减
在之前的BLOG中,我们讨论了随机梯度下降以及梯度下降算法的其他一些变种,还包括如何将其运用于在线学习。然而所有这些算法都只能在一台计算机上运行,但是实际上有些机器学习问题太大以至于不可能只在一台计算机上运行,有时候它涉及的数据量如此巨大以至于不论我们使用何种算法都不希望只使用一台计算机来处理这些数据。因此在这一部分我希望向你们介绍进行大规模机器学习的另一种方法称为映射约减 (map reduce) 方法。
尽管我们用了很大的篇幅来讲解随机梯度下降算法而我们将只用一小部分来介绍映射化简,但是请不要根据我所花的篇幅长短来判断哪一种技术更加重要,事实上许多人认为映射化简方法至少是和随机梯度下降算法同等重要的,还有人认为映射化简方法甚至比梯度下降方法更重要。我们之所以只在映射化简上花的时间比较少只是因为它相对简单容易解释。然而实际上相比于随机梯度下降方法,映射化简方法能够处理更大规模的问题。这个方法的操作方法如下。
假设我们要拟合一个线性回归模型或者逻辑回归模型或者其他的什么模型,让我们再次从随机梯度下降算法开始吧。下图就是我们的随机梯度下降学习算法,其中将假定m固定为400个样本:
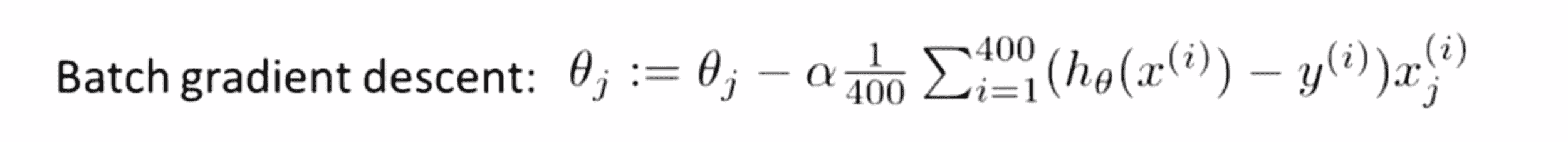
当然根据大规模机器学习的标准,m等于400实在是太小了,也许在实际问题中我们更有可能遇到样本大小为4亿的数据或者其他差不多的大小的数据。但是为了使我们的讲解更加简单和清晰我们假定我们只有400个样本。这样一来随机梯度下降学习算法中在求和中i从1取到400,如果m很大那么这一步的计算量将会很大。因此下面我们来介绍映射化简算法。这里我必须指出映射化简算法的基本思想来自Jeffrey Dean和Sanjay Ghemawat 这两位研究者,Jeff Dean是硅谷最为传奇的一位工程师,今天谷歌 (Google) 所有的服务所依赖的后台基础架构有很大一部分是他创建的。
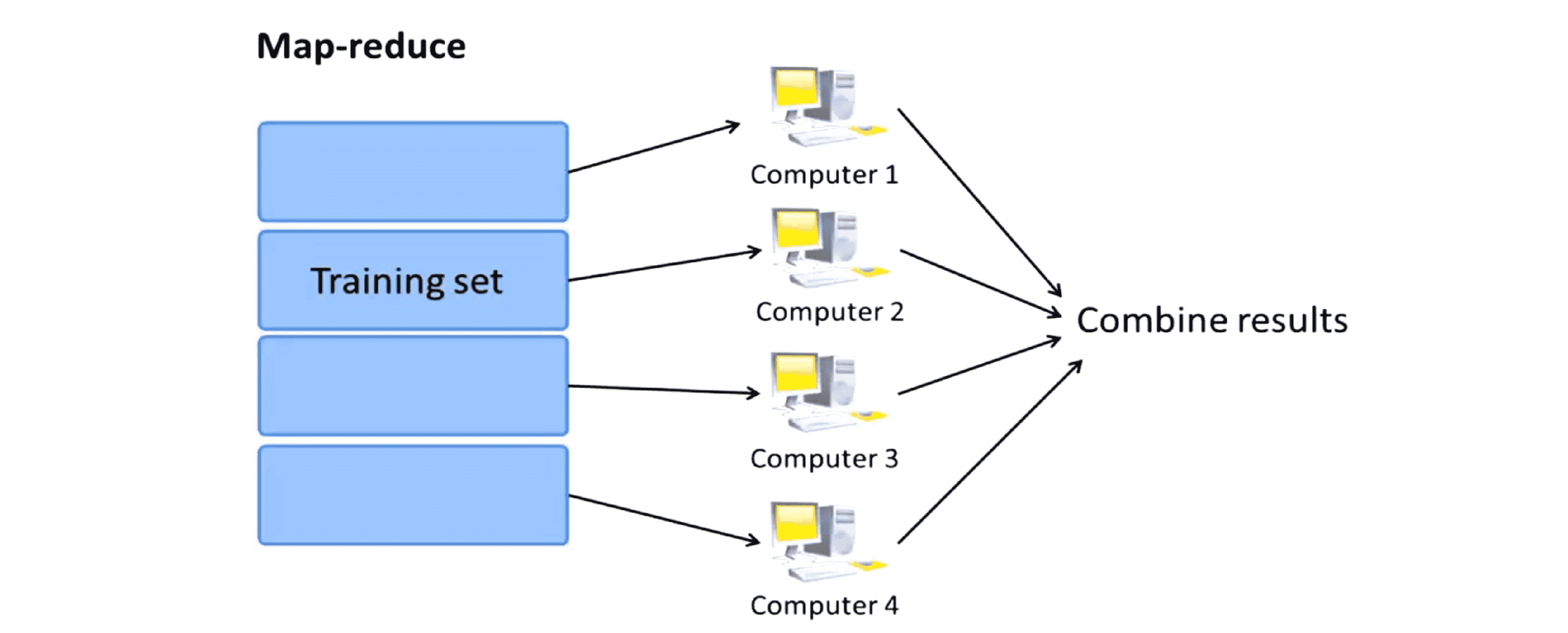
我们还是回到映射化简的基本思想,假设我们有一写训练样本,从x(1) y(1)开始,涵盖我所有的400个样本直到x(m) y(m);根据映射化简的思想一种解决方案是将训练集划分成几个不同的子集。我们假定有 4 台计算机它们并行的处理我的训练数据因此我要将数据划分成4份平均分给这4台计算机:

如果我拼命有10台计算机或者100台计算机那么也可能会将训练数据平均划分成10份或者100份。我的4台计算机中第一台将处理前四分之一训练数据,也就是前100个训练样本。具体来说这台计算机将参与处理将处理前100个训练样本进;同样地我们将用第二台计算机处理我们的第二个四分之一数据,也就是说我的第二台计算机将使用第101到200号训练样本;三个和第四个四分之一训练样本也同样分给第三台和第四台计算机。这样现在每台计算机不用处理400个样本,而只用处理100个样本,它们只用完成四分之一的工作量,这样就可以将运算速度提高到原来的四倍。
最后当这些计算机全都完成了各自的工作,我会将这些临时变量收集到一起将它们送到一个中心计算服务器这台服务器会将这些临时变量合并起来:
具体来说,它将根据以下公式来更新参数θj 新的θj = θj - α * 1 / 400 * temp(1)j + temp(2)j + temp(3)j + temp(4)j。 当然对于j等于0的情况我们需要单独处理,因为它恒等于1。其中的temp(1)j temp(2)j temp(3)j 和 temp(4)j 是我们四台电脑分别的计算结果,我们的最后的服务器只是把它们加了起来。很显然这四个临时变量的求解过程加最后的求和过程所运算出来的结果和原先我们使用批量梯度下降公式计算的结果是一样的。所以总结来说映射约减技术是这么工作的,我们有一些训练样本,如果我们希望使用4台计算机并行的运行机器学习算法,那么我们将训练样本等分尽量均匀地分成4份,然后我们将这4个训练样本的子集送给4台不同的计算机,每一台计算机对四分之一的训练数据进行求和运算,最后这4个求和结果被送到一台中心计算服务器负责对结果进行汇总。
在上一个例子中梯度下降计算的内容是对i等于1到400这400个样本进行求和运算,更宽泛的来讲在梯度下降计算中我们是对i等于1到m的m个样本进行求和。现在因为这4台计算机的每一台都可以完成四分之一的计算工作,因此我们可能会得到4倍的加速,特别的如果没有网络延时也不考虑通过网络来回传输数据所消耗的时间,那么我们可能可以得到4倍的加速。当然在实际工作中因为网络延时数据汇总额外消耗时间以及其他的一些因素,我们能得到的加速总是略小于4倍的。但是不管怎么说这种映射化简算法确实让我们能够处理更大规模的数据。
如果我们打算将映射化简技术用于加速某个机器学习算法,也就是说我们打算运用多台不同的计算机并行的进行计算,那么我们需要问自己一个很关键的问题,那就是我们的机器学习算法是否可以表示为训练样本的某种求和。事实证明很多机器学习算法的确可以表示为关于训练样本的函数求和,而在处理大数据时这些算法的主要运算量就在于对大量训练数据求和,因此只要我们的机器学习算法可以表示为训练样本的一个求和,那么我们可以考虑使用映射化简技术来将你的算法扩展到非常大规模的数据上。
让我们再看一个例子,假设我们想使用某种高级优化算法比如说 LBFGS 算法或者共轭梯度算法等等来解决逻辑回归算法。在这种算法中我们需要计算两个值:
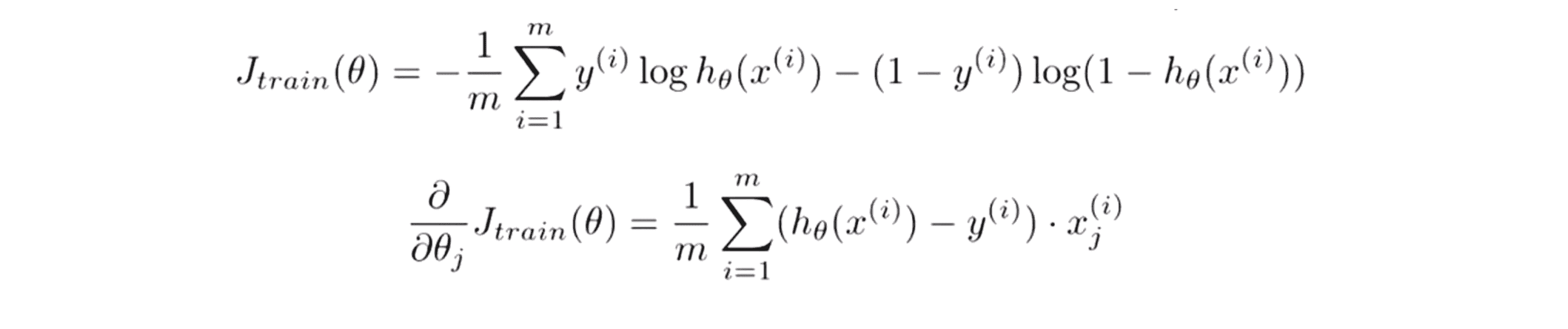
第一个值是我们需要提供一种方法用于计算优化目标的代价函数值,因此如果我们想在10台计算机上并行计算,那么我们需要将训练样本分给这10台计算机,让每台计算机计算10份之一;同样的对于逻辑回归需要提供第二个值也就是这些偏导数,其可以表示为一些训练数据的求和,因此和之前的例子类似我们可以让每台计算机只计算部分训练数据上的求和,最后在一台中心计算服务器上进行求和汇总。
因此更广义的来说,通过将机器学习算法表示为求和的形式或者是训练数据的函数求和形式,我们就可以运用映射化简技术来将算法并行化,这样就可以处理大规模数据了。最后再提醒一点目前我们只讨论了运用映射化简技术在多台计算机上实现并行计算,也许是一个计算机集群,也许是一个数据中心中的多台计算机。但实际上有时即使我们只有一台计算机,我们也可以运用这种技术。具体来说现在的许多计算机都是多核的,也就是说我们的电脑可以有多个CPU,而每个CPU又包括多个核。如果我们有一个很大的训练样本,那么我们可以使用一台四核的计算机,即使在这样一台计算机上我们依然可以将训练样本分成几份,然后让每一个核处理其中一份子样本:
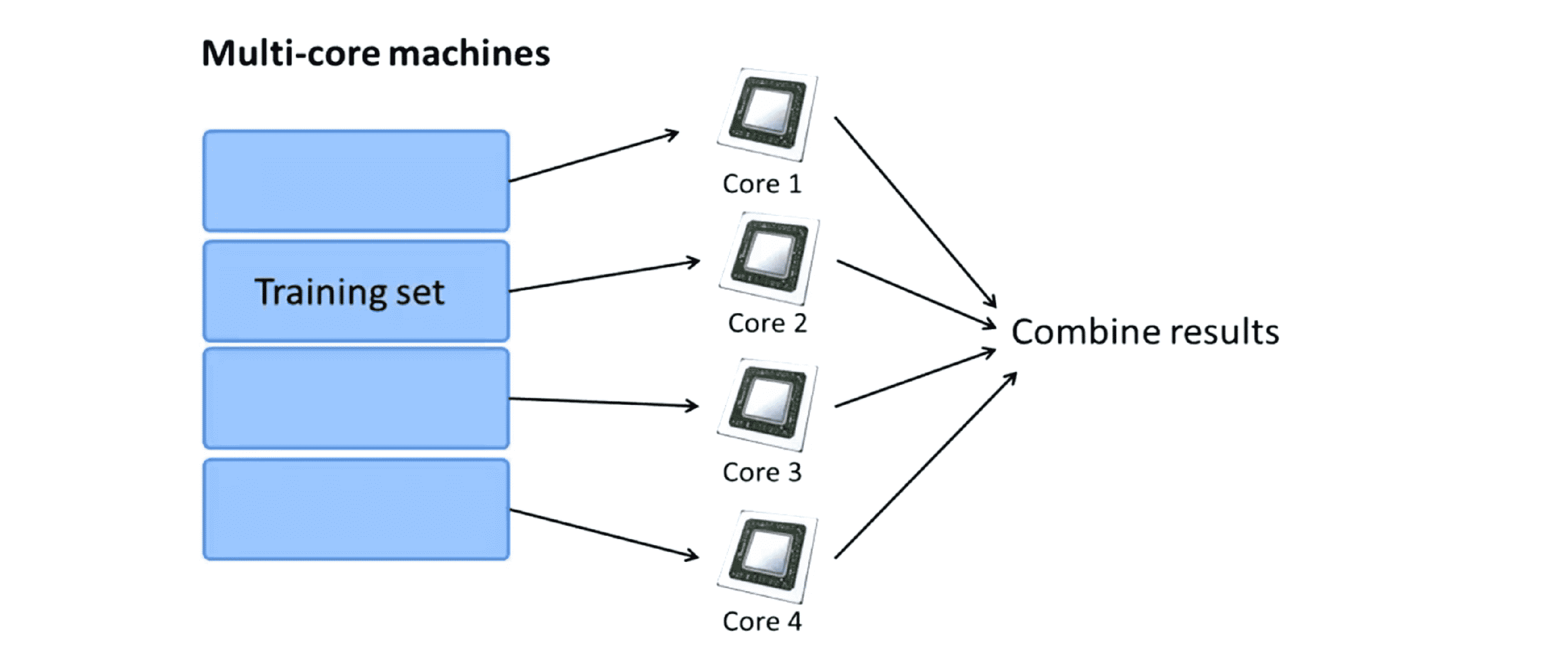
这样,在单台计算机或者单个服务器上,我们也可以利用映射化简技术来划分计算任务,每一个核可以处理比方说四分之一的训练样本的求和,然后我们再将这些部分和汇总最终得到整个训练样本上的求和。相对于多台计算机这样在单台计算机上使用映射化简技术的一个优势在于现在我们不需要担心网络延时问题,因为所有的通讯所有的来回数据传输都发生在一台计算机上,因此相比于使用数据中心的多台计算机,现在网络延时的影响小了许多。
最后关于在一台多核计算机上的并行运算我再提醒一点,这取决于你的编程实现细节。如果我们有一台多核计算机并且使用了某个线性代数函数库,那么请注意某些线性代数函数库会自动利用多个核并行地完成线性代数运算,因此如果我们幸运地使用了这种线性代数函数库,并且我们有一个矢量化得很好的算法实现,那么有时只需要按照标准的矢量化方式实现机器学习算法而不用管多核并行的问题,因为我们的线性代数函数库会自动帮助你完成多核并行的工作。因此这时你不需要使用映射化简技术。
但是对于其他的问题使用基于映射化简的实现寻找并使用适合映射化简的问题表述然后实现一个多核并行的算法可能是个好主意,它将会加速你的机器学习算法。现在网上有许多优秀的开源映射化简实现,实际上一个称为Hadoop 的开源系统已经拥有了众多的用户,通过自己实现映射化简算法或者使用别人的开源实现都可以利用映射化简技术来并行化机器学习算法,这样我们的算法就将能够处理单台计算机处理不了的大数据。
结语
在这篇BLOG中,我们一同学习了机器学习处理大数据的两个利器在线学习和映射约减,希望能对你有所帮助。最后希望你喜欢这篇BLOG!

