在这一篇BLOG我想向你介绍一种机器学习的应用实例或者说是机器学习在一种叫照片OCR技术中的应用历史,我想介绍这部分内容的原因主要有以下三个:第一我想向你展示一个复杂的机器学习系统是如何被构建起来的;第二我想介绍一下机器学习流水线(machine learning pipeline)的有关概念;最后我也想通过介绍照片OCR问题的机会来告诉你机器学习的诸多有意思的想法和理念。
照片OCR问题
好的那么我们就从什么是照片OCR问题开始。所谓照片OCR,其表示的就是照片光学字符识别(photo optical character recognition)。随着数码摄影的日益流行以及近年来手机中拍照功能的逐渐成熟,我们现在很容易就会有一大堆从各地拍摄的数码照片吸引众多开发人员,其中一个应用是如何让计算机更好地理解这些照片的内容。这种照片OCR技术主要解决的问题是让计算机读出照片中拍到的文字信息。让我们用下面这样一张照片举例说明:

看到这张照片,人们就会想:如果计算机能够读出照片中的文字就太好了,这样一来如果我们下次想再把这张照片找出来时,我们就可以通过输入照片中的文字 LULA B's ANTIQUE MALL ,然后让计算机就自动地找出这张照片来,而不用花几个小时把我们的相片集翻个底朝天,从几百上千张照片中把这张找出来。
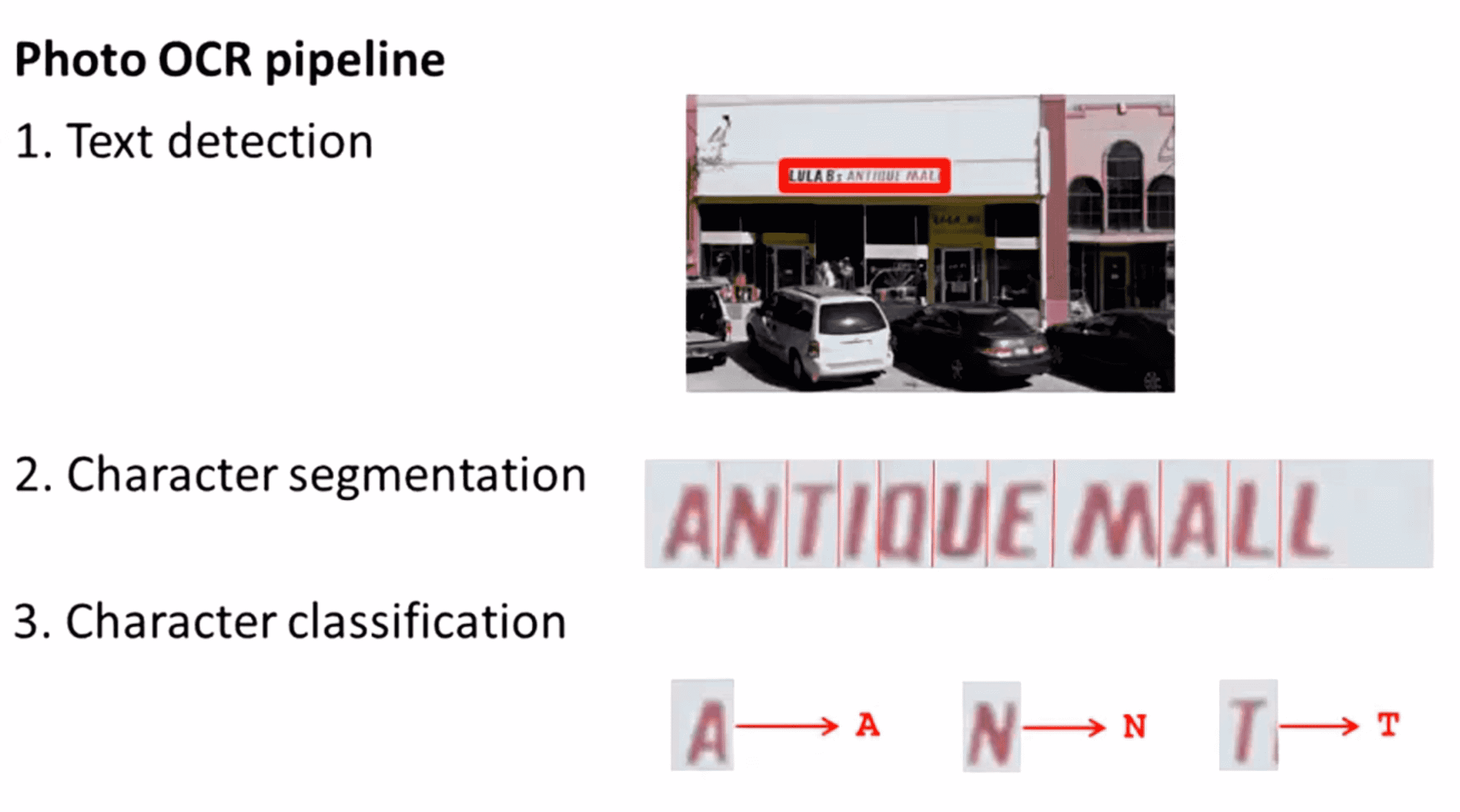
照片OCR就是解决这一问题的,它有如下几个步骤:首先给定某张图片,它将把图像浏览一遍然后找出这张图片中哪里有文字信息:

在完成这一步以后,接下来要做的就是重点关注这些文字区域,并且在这些区域中对文字内容进行识别。如果能正确读出的话,它会将这些内容进行转录记录下图片中出现的这些文本:

虽然现在OCR或者说光学文字识别对扫描的文档来说已经是一个比较简单的问题了,但对于数码照片来说现在还是一个比较困难的机器学习问题。研究这个目的不仅仅是因为可以让计算机更好地理解我们的户外图像,更重要的是它衍生了很多应用,比如在帮助盲人方面——假如我们能为盲人提供一种照相机,这种相机可以“看见” 他们前面有什么东西,可以告诉他们面前的路牌上写的是什么字那将极大地造福盲人的生活。现在也有研究人员将照片OCR技术应用到汽车导航系统中,想象一下假如我们的车能读出街道的标识并且将我们导航至目的地那该有多棒。
要实现照片OCR我们可以这样做:首先我们可以通览图像并找出有文字的图像区域。这里展示的例子就是照片OCR系统可能会识别到的图像中的文字信息:

接着我们通过得到的文字区域的矩形轮廓可以进行字符切分。比如对这个文字框,我们或许能认出“ANTIQUE MALL”,然后我们会试着将其分割成独立的字符:

最后在成功将字段分割为独立的字符后,我们可以运行一个分类器,通过输入这些可识别的字符然后试着识别出其分类,比如下图中第一个字母是一个A,第二个字母是一个N,第三个字母是一个T等等:

因此通过完成所有这些工作,按理说我们就能识别出这个字段写的是 LULAB's ANTIQUE MALL,然后图片中其他有文字的地方也是类似的方法进行处理。实际上有很多照片OCR系统会进行更为复杂的处理,比如在最后会进行拼写校正,比如说假如我们的字符分割和分类系统告诉我们它识别到的字是 “C 1 e a n i n g” 那么,很多拼写修正系统会告诉我们这可能是单词 “Cleaning”的拼写,可能我们的字符分类算法刚才把字母 l 识别成了数字 1 ,但在这篇BLOG中我们要做的事情不会考虑最后这一步,我们只关注前面三个步骤也就是文字检测、字符分割以及字符分类。
那么像这样的一个系统,我们把它称之为机器学习流水线(machine learning pipeline)。具体来说,下面这幅图表示的就是照片OCR的流水线:
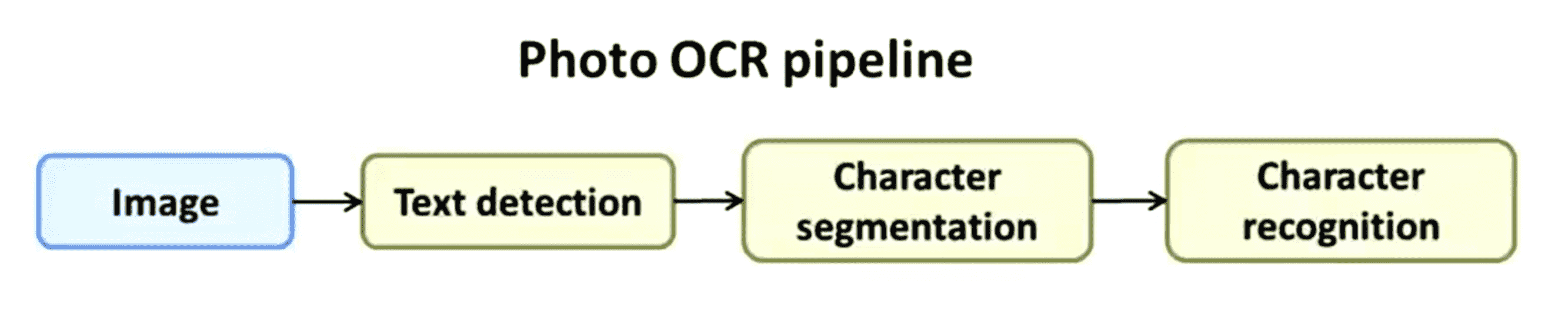
我们有一幅图像我们首先将它传给文字检测系统,识别出文字以后我们将字段分割为独立的字符,最后我们对单个的字母进行识别。在很多复杂的机器学习系统中这种流水线形式 非常普遍,在流水线中会有多个不同的模块,比如在本例中我们有文字检测、字符分割和字母识别三个模块,其中每个模块都可能是一个机器学习组件或者有时候这些模块也不一定是机器学习组件,只是一个接一个连在一起的一系列数据处理,并在最终得出我们希望的结果,比如在照片OCR例子中就是最终识别到的图片中的文字信息。如果我们要设计一个机器学习系统,其中需要作出的最重要的决定就是我们要怎样组织好这个流水线。换句话说在这个照片OCR问题中,我们应该如何将这个问题分成一系列不同的模块并设计这个流程以及流水线中的每一个模块,这通常会影响到我们最终的算法的表现。如果我们有一个工程师的团队,在完成同样类似的任务那么通常我们可以让不同的人来完成不同的模块,比如我可以假设文字检测这个模块需要大概1到5个人,字符分割部分需要另外1到5个人,字母识别部分还需要另外1到5个人。因此使用流水线的方式通常提供了一个很好的办法来将整个工作分给不同的组员去完成。当然所有这些工作都可以由一个人来完成,如果我们一定要这样做的话。
在复杂的机器学习系统中,流水线的概念已经渗透到各种应用中。正如你刚才看到的照片OCR,流水线的运作过程在接下来的几个部分中我还将继续向你介绍更多的细节。
滑动窗口
在上一部分中,我们谈到了照片 OCR 流水线以及其工作原理。我们讲到可以照一张照片然后将其通过一系列机器学习组件来尝试读出图片中的文字信息。在这一部分中,我想再多介绍一些照片OCR流水线中的组件是如何工作的,具体来说这一部分的大部分内容将关注一种叫滑动窗(sliding windows)的分类器。
滑动窗的第一个步骤是文字检测(text detection) 我们有下面这样一幅照片,并且想要找出图片中出现文字的区域。文字识别是计算机视觉中的一个非同寻常的问题,因为取决于我们要找到的文字的长度,这些长方形区域会呈现不同的宽高比:

为了更好地介绍图像的检测,我们从一个简单一点的例子开始。我们先看这个探测行人的例子,等下再把我们从行人检测中得出的想法应用到文字检测中。在行人检测中我们希望照一张相片,然后找出图像中出现的行人:

所以上图中红框选中的就是我们找到的行人。这个问题似乎 比文字检测的问题更简单,其原因是大部分的行人都比较相似,因此可以使用一个固定宽高比的矩形来分离出你希望找到的行人。这里提到的宽高比指的是这些矩形的高度和宽度的比值。在行人的问题中,不同矩形的宽高比都是一样的,但对文字检测的问题高度和宽度的比值对不同行的文字就是不同的了。虽然在行人检测的问题中,行人可能会与相机处于不同的距离位置导致这些矩形的高度不同,但这个比值应该都是一样的。
为了建立一个行人检测系统,以下是具体步骤。假如说我们把宽高比标准化到82比36这样一个比例,我们也可以把这个比值进行圆整比如化为80比40之类的,但82比36也可以。接下来我们要做的就是到街上去收集一大堆正负训练样本:

左边是82×36大小的有行人的图像样本,而右边这些样本里没有行人样本,在这里我们各展示 12 个样本,也就是12个正样本 y = 1 以及12个负样本 y = 0。在更典型的行人识别应用中,我们可以有1000个训练样本到10000个训练样本不等甚至更多,如果我们能得到大规模训练样本的话接下来要做的事就是训练一个神经网络或者别的什么学习算法,输入这些图片82×36维的图像块然后对 y 进行分类,把图像块分成"有行人" 和"没有行人"两类。因此这一步实际上是一个监督学习,我们通过一个图像块来决定这个图像块里有没有行人。
现在假如我们获得一张新的图像一个测试集图片就像下面这张图,我们想来试试看在这张图片中找行人:

我们要做的是先对这个图像取一小块长方形,就像上图中所示的,比如这是一个 82×36的图像块。然后我们将这个图像块通过我们训练得到的分类器来确定这个图像块中是不是有行人。如果没问题的话我们的分类器应该报告这个图像块 y=0,因为其中没有行人。接下来,我们把这个绿色的长方形图片滑动一点点,然后得到一个新的图像块,并同样把它传入我们的分类器看看这里面有没有行人:

做完这以后,我们再向右滑动一点窗口然后同样地把图像块传入分类器:

我们每次滑动窗口的幅度大小也是一个参数,其通常被称为 步长(step size),有时也称为步幅参数(stride parameter) ,如果我们每次移动一个像素,就是说我们是用的步长或者说步幅是1,这样通常表现得最好但可能计算量比较大;因此通常使用4个像素作为步长值或者每次8个像素或者每步选择更大的像素都是比较常见的。通常整个过程就是我们一点点连续向右移动这个小的矩形窗,并且每次都将图像块通过我们的分类器直到最后你滑动小窗遍历图片中的不同位置。从一开始在第一行滑动然后到图片中的下面几行:

我们会逐渐地以某个步长或步幅把这些图像块全部放入我们的分类器并运行。但这个矩形是非常小的,只能探测到某种尺寸的行人,所以接下来我们要做的是看看更大的图像块。因此我们用更大一些的图像块就像下图这里所示的:

同样地我们将窗口内的图像传入分类器运行。顺便说一下我说"用更大一些的图像块" 的意思是当我们用这样的图像块时,我们先取出这个图像块然后把这张图像块重新压缩到82×36的尺寸,就是说我们先取一个大一点的图然后重新把大小调整到小的尺寸或者说调整到可以传入确定图片中是否有行人的分类器应该使用的尺寸。最后我们可以做一个更大的矩形同样滑动窗口……
到最后完成整个过程以后我们的算法应该就能检测出图像中是否出现行人了:

接下来我们转向文字识别的例子,让我们来看看对于照片 OCR 流水线中要检测出文字需要怎样的步骤:
跟行人检测类似,我们也可以先收集一些带标签的训练集包括正样本和负样本分别对应文字出现的区域,只是跟刚才不同的是 现在我们要检测文字而不是行人。因此正样本就表示图像中有文字的那些图片,而负样本表示没有文字图像的图片。训练完了以后我们就可以把它应用到新的图像中,或者说测试集图片中。我们以下面这幅左边图片为例:

我们假设对于这个例子,为了表达方便我们用一个固定的比例来运行滑动窗,也就是说我只用一种矩形尺寸。假如说我用许多很小的矩形图片来运行矩形窗算法,拿白色的区域表示我的文字检测系统已经发现了文字,而黑色的区域就表示在原图中分类器在这一个区域没有找到任何文字,并且不同的灰度就表示分类器给出的输出结果的概率值,所以比如有些灰色的阴影这就表示分类器似乎发现了文字但并不十分确信,而比较白亮的区域则表示分类器预测这个区域有文字有比较大的概率。所以这两幅图的坐标是对应的。现在我们还没完成文字检测呢,因为我们实际上想做的是在图像中有文字的各区域都画上矩形窗,所以我们还需要完成一步我们取出分类器的输出然后输入到一个被称为"展开器"(expansion operator)的东西,展开器的作用就是会取过这张图片对每一个白色的小点都扩展为一块白色的区域,就如上图的右边那样。从数学上说这一步实现就是看右边这幅图我们得到右边这幅图的做法就是对于每一个像素我们都考察一下它是不是在左边或右边的五或十个像素范围中还要白色的像素,如果有将把右边那幅图的相同像素设为白色。因此这样做的效果就是我们把左边图中的所有的白色小点根据它们周围临近像素是不是白色的都扩展了一下,让它们都变大了一些。这样我们就快完成了,我们现在可以根据右边的这张图锁定那些连接部分也就是这些连续的白色区域,然后围绕着它们画个框就行了。好的这就是使用滑动窗来进行文字检测的过程。
找到这些有文字的长方形以后,我们现在就能够剪下这些图像区域然后应用流水线的后面步骤对文字进行识别。如果你还记得的话你应该知道流水线的第二步是字符分割,所以给出上面这样的图像我们应该怎样分割出图像中的单个字符呢? 同样地我们还是使用一种监督学习算法,用一些正样本和一些负样本,而我们要做的就是看看这些图片然后试着决定一下图像中是不是在两个字符之间有一条分界线:
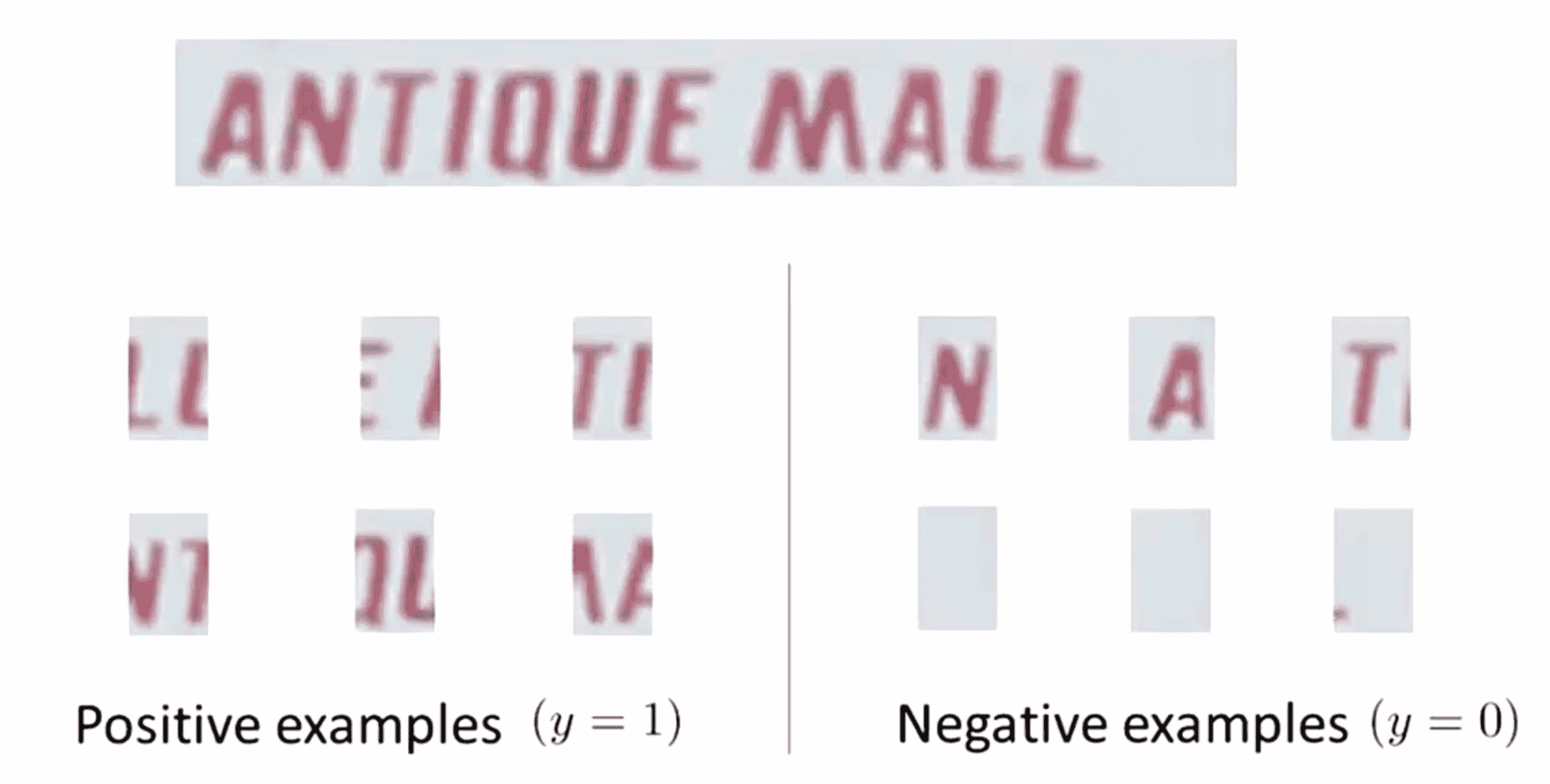
所以对上面这些正样本比如第一个样本,这个图片中间似乎就有一条分界线把两个字符分开了,所以这些都是正样本;而对于负样本,我们似乎不能在中间画一条分隔线来把左右分开,所以这些都是负样本。因此我们要做的就是 训练一个分类器,可以用神经网络也可以用别的学习算法来试着对这些正负样本进行分类,训练好这个分类器以后我们就要把这个分类器应用到我们文字中。我们使用滑动窗口提取一个个小矩形,我们要问分类器这个矩形窗的中间部分是不是像两个字符的中间分割位置呢,值得一提在这里我们滑动矩形窗是一个一维的矩形窗分类器,因为我们滑动矩形窗的方向就是沿着一条直线从左向右不存在其他行。随着我们的窗口慢慢向右移动,我们的分类器会输出一些正样本帮助我们分割为独立的字符。这就是用于字符分割的一维滑动窗,最后效果大致如下:
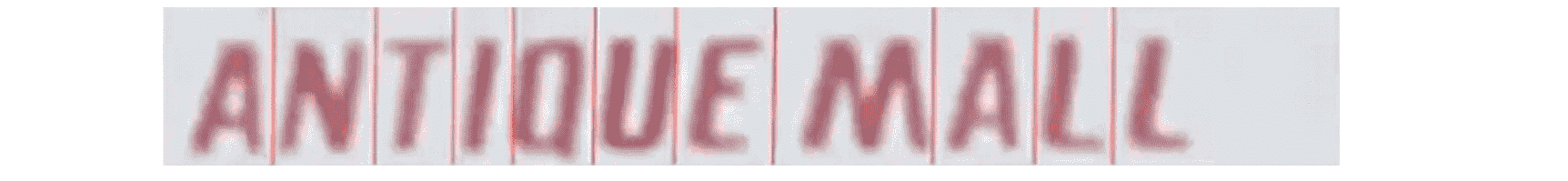
处理完成后,我们又回到了整个照片OCR流水线,在文字检测中我们使用滑动窗来检测文字,同时我们还用了一个一维滑动窗来进行字符的分割来将图像分割为独立的字符。在流水线的最后一步字符分类,这一步根据之前我们已经学到的监督学习算法就应该比较清楚应该怎么做了。我们可以使用一种标准的监督学习算法,比如神经网络或者其他方法对输入这样的图像按字母分类化为26个字母 A到Z中的一个:

或者我们也可以算上标点分类成36种字符。这就是一个多元分类问题,我们应该把这个带有字符的图像作为输入,然后确定这个图像中出现了什么字符。这就是照片OCR流水线技术以及使用滑动窗作为分类器来把这些不同的组件放在一起共同开发成一个照片OCR系统的过程,其完整步骤如下:
在下一部分中我们将继续围绕照片OCR技术探究其他一些有趣的应用问题。
人工数据生成
当你得到一个照片OCR系统后,要做的下一步就是进行优化使其变得更加高效。我在很多篇BLOG中都提到过,要想获得一个比较高效的机器学习系统,其中一种最可靠的办法是选择一个低偏差的学习算法,然后用一个巨大的训练集来训练它。但我们从哪儿得到那么多的训练数据呢? 其实在机器学习中有一个很棒的想法叫做“人工数据合成”(artificial data synthesis),这个概念不针对某一个具体的问题,要解决某个具体的问题通常还是依赖某个具体的思想方法和观点,但如果我们把这个概念应用到我们所有的机器学习问题中,我们有时就能用一种很容易的方法来为学习算法获取大量的训练集数据。
人工数据合成的概念通常包含两种不同的变体,第一种是我们白手起家来创造新的数据;第二种是我们已经有了一小部分带标签的训练集,我们通过人工合成可以扩大这个训练集,也就是说用一个小的训练集将它扩充为一个大的训练集。这这一部分我们将对这两种方法进行介绍。
为了介绍人工数据合成的概念让我们还是用之前用过的照片OCR流水线中的字母识别问题。假如我们输入一个图像数据然后想识别出是什么字母,假如我们可以在别处收集到一大堆标签数据如下图:

在这个例子中,我们选择的是正方形长宽比的图像也就是我们选用正方形的图像块,目标就是对任意一个图像块我们要能识别出图像中心的那个字符。同时为了方便我们把这些图像都视为灰度图像而不是彩色图像,实际上用彩色的图像对这个问题的解决也起不了多大作用。所以对第一个图像块,我们会识别出中心的字符是一个T,而考虑第二个图像块我们会将它识别为一个M……等等,所有这些就是我们的原始图像。那我们怎样获得一个更大的训练集呢?现代计算机通常都有一个很大的字体库,如果我们使用一个文字处理软件,我们就会有所有这些字体或者别的很多很多字体已经储存在字体库中这取决于你用的是哪个文字处理软件,同样地如果我们登陆一些的网站依然会发现大量的免费的字体库可供你下载,通常有成百上千种不同类型的字体样式。所以如果我们想要获得更多的训练样本,其中一种方法是我们可以采集同一个字符的不同种字体然后将这些字符加上不同的随机背景:

在我们做完以上工作以后,我们就得到了一个合成后的训练集就像右图所示,右图中每一个图像实际上都是一个合成后的图像。我们先得到一种字体也许是从网上随便下载的然后把这个字符的图像或者一系列字符的图像粘贴到其他随机的背景图像前面,然后应用某个模糊操作。模糊的意思是让图像变形,比如均匀、等比例缩放或者一些旋转操作等等,在完成这些操作后我们就得到了这个合成后的训练集,就是上图右边所示的。而要完成这项工作还是需要仔细考虑才能得到比较真实的合成数据,如果我们搞得很草率的话,获得的合成数据很可能就不是那么好,这取决于我们合成的方法。但如果我们仔细看这次合成数据的话会发现它们跟真实数据还是非常接近,因此通过使用合成的数据实际上我们已经可以获得无限的训练样本了,这就是人工数据合成。所以如果你使用这种合成数据的话,我们实际上也就有了无限的有标签数据,我们就可以用它来进行监督学习来解决这个字符识别的问题。这便是一种人工数据合成的实例,我们基本上是在完全创造新的数据,创造新的图像数据。
人工数据合成的第二种方法是使用我们已经有的样本。我们选取一个真实的样本,经过操作生成新的样本来扩大我们的训练集。比如在下图中,这里这幅图像是一个字母A来自于一个真实的图像,我们在图像上加了一些灰色的网格。我们要做的就是取出这个字母A 进行人工扭曲或者人工变形这样从一个图像A就能生成16种新的样本:
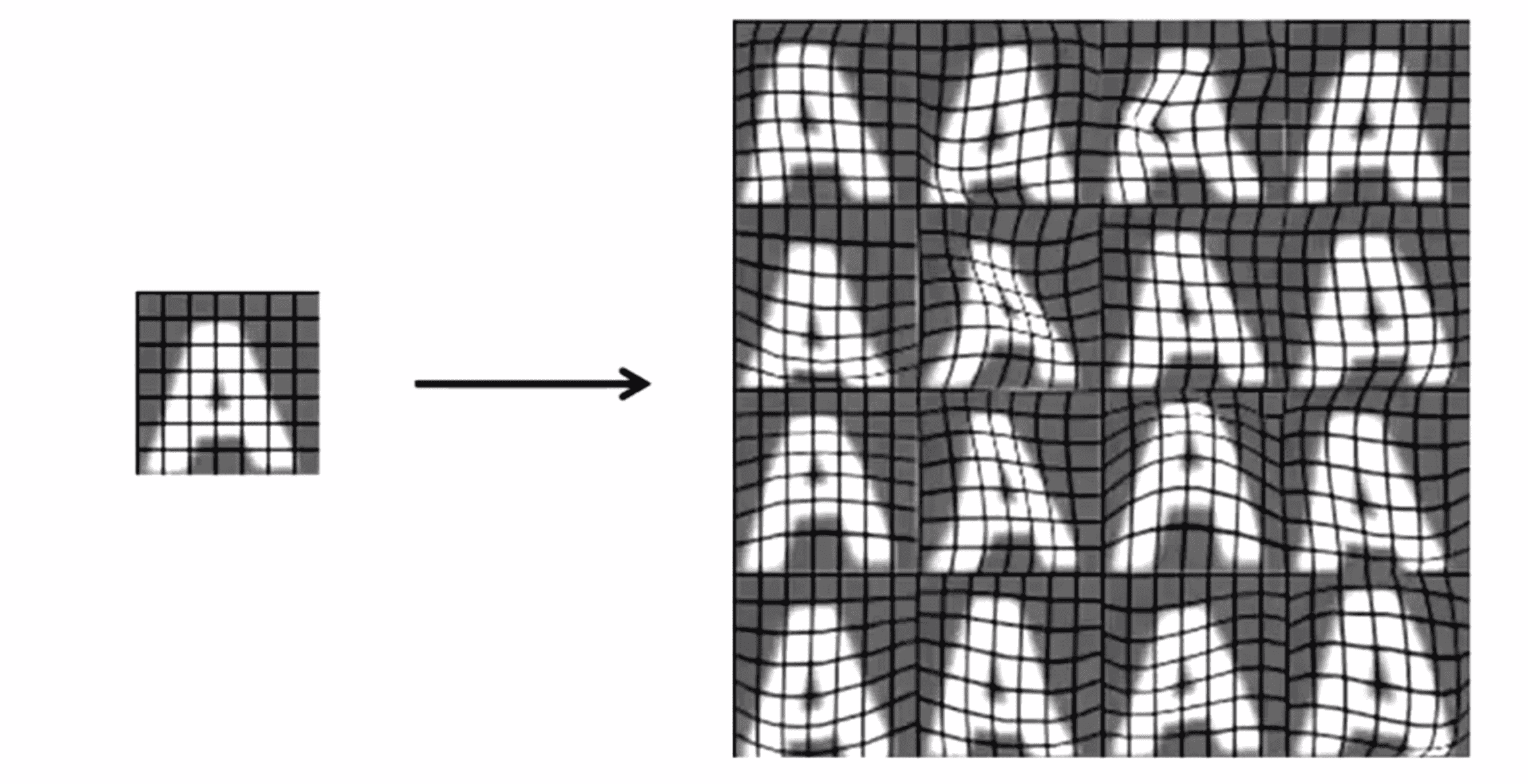
所以用这种方法我们可以把一个很小的带标签训练集突然一下扩大得到更多的训练样本。同样地要把这个概念投入应用,还是需要仔细考虑的。比如要考虑什么样的变形是合理的或者说怎样才是合理的方法来扩大我们的训练集。对这个特定的字母识别的例子引入,我们应该如何扩大数据呢?其中一种方法是为这组数据引入额外的变形,我们可以引入的干扰或变形来制造新的训练集:

对于字符识别这个例子这种扭曲的方法,事实上还是很合理的。因为像这种扭曲的图像A的情况,我们确实有可能在测试集中会遇到比如这个胖胖的A 或者其他别样的写法。
相对而言我们有另一种方法就是为我们的数据添加一些纯随机的噪声,如下图:

我不确定你从这里能否看出,但在这里我做的是这四幅图像中每一个图像的每一个像素我都加了一些随机高斯噪声,所以对每个像素点也就是像素点的亮度就只是加了一些高斯随机噪声,因此这是完全没有意义的对吧?因此 除非你觉得你会在你的测试集中遇到这些像素的噪声,否则的话这些随机的噪声是无意义的,起不来多大作用。
但是人工数据合成的过程,怎么说呢,它并没有什么技巧可言,有时候你只能一种种方法一遍遍地尝试然后观察效果,但我们在确定需要添加什么样的变形时就一定要考虑好我们添加的那些额外的变形量是否是有意义的,这样能让你产生的训练样本至少在某种程度上具有一定的代表性,能代表我们可能会在测试集中看到的某种图像。
最后来总结一下这节视频,我还想多说一些关于这种通过人工数据合成获得大量数据的方法。首先,同往常一样在花费大量精力考虑如何产生大量人工训练样本之前,我们通常最好应该先保证我们已经有了一个低偏差的分类器,这样得到大量的数据才真的会起作用。我们标准的方法是画出学习曲线,然后确保我们已经有了一个低偏差或者高方差的分类器或者我们直接增大分类器的特征数或者在神经网络中增大隐藏层单元数,直到我们得到一个偏差比较小的分类器,直到这时我们再来考虑建立大量的人工训练集。所以我们一定要避免的是花了几个星期的时间或者几个月的工夫考虑好了怎么样能获得比较好的人工合成数据,然后才意识到即使获得了大量的训练数据,自己的学习算法的表现依然没有提高多少。这就是我对你的一点建议,在你花费大量精力获得大量人工训练集数据之前,建议应该先做这样一个测试。
其次当我在解决机器学习问题时,通常那些专家都会问他们的团队或者他们的学生,他们要付出多少工作量才能获得10倍于我们现有的数据量。每当他们面对一个新的机器学习应用问题,他们总会先跟团队坐在一起讨论这个问题。大多数情况下他们团队的回答都是这并不是什么难事,最多花上几天时间就能给一个机器学习问题获得十倍于现有数据量的数据。而且通常来说如果能得到10倍的数据量,那么一般都能让学习算法表现更好。因此如果我们加入某个产品设计小组要设计某个机器学习的应用产品,那么这也是一个很好的问题,我们可以问问自己问问团队,也不必太惊讶说不定几分钟的头脑风暴以后我们的团队就会想出一种方法真的一下子能获得 10倍的数据量。这样的话我想我们能成为这个团队的英雄,因为有了10倍的数据我们通过学习这么多的数据一定会获得更好的学习表现。
为了提高我们系统性能,我们其实还有很多其他办法可以尝试,在本部分中我们主要关注人工数据合成,这既包括从零开始生成新数据比如使用随机的字体等等,也包括第二种思路那就是在现有的样本中引入一些噪声或变形来扩大现有的训练样本。在生成大量数据之前,我们通常进行的一种计算是问问自己需要花多少分钟或者多少小时来获得一定量的样本数,比如我们需要花10秒的时间来标记一个样本,假设对于我们的应用,我们现在要获得1,000组带标签的样本,所以10乘以1,000等于10,000,我们需要花大约3小时来生成我们所需要的数据。因此如果我们算一下的话,通常很多团队都表现得相当惊讶,发现所需要的时间那么少!有时候需要两三天有时候需要几天就能得到10倍于原来的数据量,且能让我们的学习算法在表现上获得一个巨大的提高。
除了自己制造数据,是另一种很好的办法是我们称之为"众包" (crowd sourcing) 的办法。现在已经有一些网站或者一些服务机构能让我们通过网络雇一些人替我们完成标记大量训练数据的工作。通常这都很廉价,因此这种众包的方法或者叫众包的数据标记非常受人欢迎。很明显这种方法就像学术文献一样也是很复杂的,其也同时取决于标记人的可靠性。也许世界上有成百上千的标记人用很低的收入帮你为数据加上标签,就像刚才说的这也是一种选择而已。可能“亚马逊土耳其机器人”(Amazon Mechanical Turk) 就是当前最流行的一个众包选择,要让它工作并获得比较高质量的标签通常还不是一件容易的事,其需要花一定的功夫,但这也是一种可供选择的方法。
在这一个部分中,我们谈到了人工数据合成的概念。这既包括从无到有地创造新的数据比如我们用到了随机字体的例子,也包括扩大训练数据的办法比如通过对已有的标签样本来制造新的标签样本的例子。最后我希望你要记住的一点是如果要解决某个机器学习问题通常有两件事情值得好好考虑的:第一是用学习曲线,进行合理性检查保证使用更多的数据能有效果;第二点是自己坐下来,认真地想一想想要得到现有数据的10倍数据量需要花费多少工作量。有时候你会非常惊讶于自己算出来的结果,也许只需要几天几个星期的时间,就能让我们的学习算法的表现有巨大的提高。
天花板分析
在前面的部分中,我不止一次地说过在你开发机器学习系统时我们最宝贵的资源就是时间。作为一个开发者我们需要正确选择下一步的工作或者也许我们有一个开发团队或者一个工程师小组共同开发一个机器学习系统,同样最宝贵的还是开发系统所花费的时间。我们需要尽量避免的情况是我们或者我们的同事我们的朋友花费了大量时间在某一个模块上,在几周甚至几个月的努力以后才意识到所有这些付出的劳动都对最终系统的表现并没有太大的帮助。在这一部分中,我们将一同学习一下关于天花板分析(ceiling analysis)的相关内容来帮助我们拜托上文中提到的困境。
当我们自己或跟我们的团队在开发机器学习系统的流水线时,天花板分析通常能提供一种很有价值的信号或者说很有用的导向告诉我们流水线中的哪个部分最值得你花时间。为了介绍天花板分析,我将继续使用之前用过的照片OCR流水线的例子:
在之前的课程中,我们讲过这些方框文字检测、字符分割和字符识别,这每一个方框都可能需要一个小团队来完成当然也可能你一个人来构建整个系统。不管怎样问题是我们应该怎样分配资源呢?哪一个方框最值得我们投入精力去做投入时间去改善效果呢?也就是说这些模块中哪一个 或者哪两个、三个是最值得我们花更多的精力去改善它的效果的?这便是天花板分析要做的事。
跟其他机器学习系统的开发过程一样,为了决定要开发这个系统应该采取什么样的行动,一个有效的方法是对学习系统使用一个数值评价量度。所以假如我们用字符准确度作为这个量度,因此给定一个测试样本图像那么这个数值就表示我们对测试图像中的文字识别正确的比例或者我们也可以选择其他的某个数值评价度量值随自己选择但不管选择什么评价量度值我们只是假设整个系统的估计准确率为72%,所以换句话说我们有一些测试集图像并且对测试集中的每一幅图像,我们都对其分别运行 文字检测、字符分割然后字符识别,然后我们发现根据我们选用的度量方法,整个测试集的准确率是72%。
下面是上限分析的主要思想:
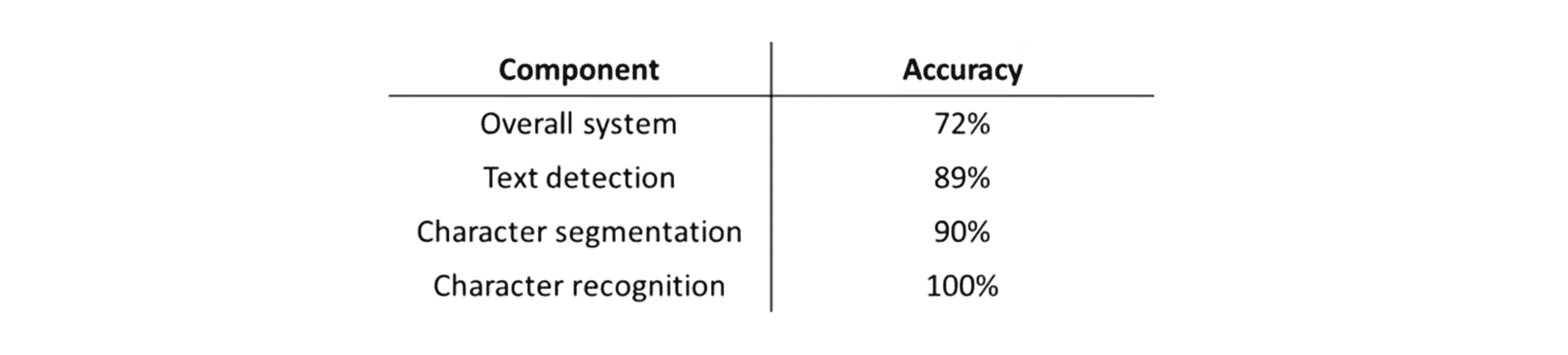
首先我们关注这个机器学习流程中的第一个模块文字检测,而我们要做的实际上是在给测试集样本捣点儿乱。我们要对每一个测试集样本,都给它提供一个正确的文字检测结果。换句话说我们要遍历每个测试集样本然后人为地告诉下一部分的算法每一个测试样本中什么地方出现了文字,因此换句话说我们是要模拟如果是100%正确地检测出图片中的文字信息,算法最后的效率应该是什么样的。当然要做到这个是很容易的,现在不用我们的学习算法来检测图像中的文字了,我们只需要找到对应的图像然后人为地识别出测试集图像中出现文字的区域,然后我们要做的就是让这些绝对正确的结果这些绝对为真的标签也就是告诉我们图像中哪些位置有文字信息的标签,把它们传给下一个模块也就是传给字符分割模块,然后我们发现一番操作后准确率提高到89%。然后我们继续进行接着执行流水线中的下一模块字符分割,同前面一样我们还是去找出我的测试集,然后现在我不仅用标准的文字检测结果还同时用标准的字符分割结果,所以还是遍历测试样本人工地给出正确的字符分割结果,然后看看这样做以后效果怎样变化。假如我们这样做以后整个系统准确率提高到90%。注意跟前面一样这里说的准确率是指整个系统的准确率所以无论最后一个模块字符识别模块给出的最终输出是什么我们都是测出的整个系统的准确率。最后我们还是执行最后一个模块字符识别,同样也是人工给出这一模块的正确标签。这样做以后我应该理所当然得到100%准确率。
进行上限分析的一个好处是,我们现在就知道了如果对每一个模块进行改善它们各自的上升空间是多大。所以我们可以看到如果我们拥有完美的文字检测模块,那么整个系统的表现将会从准确率72%上升到89%,因此效果的增益是17%。这就意味着如果你在现有系统的基础上花费时间和精力改善文字检测模块的效果,那么系统的表现可能会提高17%,看起来这还挺值得。而相对来讲如果我们取得完美的字符分割模块那么最终系统表现只提升了1%,这便提供了一个很重要的信息告诉我们不管我们投入多大精力在字符分割上,系统效果的潜在上升空间也都是很小很小。所以我们就不会让一个比较大的工程师团队花时间忙于字符分割模块,因为通过天花板分析我们知道了即使我们把字符分割模块做得再怎么好再怎么完美,我们的系统表现最多也只能提升1%。所以这就估计出通过改善各个模块的质量 你的系统表现所能提升的上限值或者说最大值是多少。最后如果我们取得完美的字符识别模块,那么整个系统的表现将提高10%,所以同样我们也可以分析10%的效果提升值得投入多少工作量,也许这也告诉我们如果把精力投入在 流水线的最后这个模块,那么系统的性能还是能得到较大的提高。
另一种认识这种分析方法的角度是通过这样的分析我们就能总结出改善每个模块的性能系统的上升空间是多少或者说如果其中的某个模块变得绝对完美时我们能得到什么收获。这就像是给系统表现加上了一个提升的上限值,所以 天花板分析的概念是很重要的。
下面我换一个复杂一点的例子再来演绎一下上限分析的原理。假如说我们想对这张图像进行人脸识别,也就是说看着这张照片希望我们识别出照片里这个人是不是我们的朋友或者希望辨识出图像中的人的相关信息。这是一个偏人工智能的例子,当然这并不是现实中的人脸识别技术,但我想通过这个例子来向你展示一个流水线并且给你另一个关于上限分析的实例。假如我们有张照片我们设计了如下的流水线:

假如我们第一步要做的是图像预处理,假如我们就用上面这张照片,现在我们想要把背景去掉。那么经过预处理背景就被去掉了:

下一步我们希望检测出人脸的位置,这通常通过一个学习算法来实现。我们会运行一个滑动窗分类器在人脸周围画一个框:

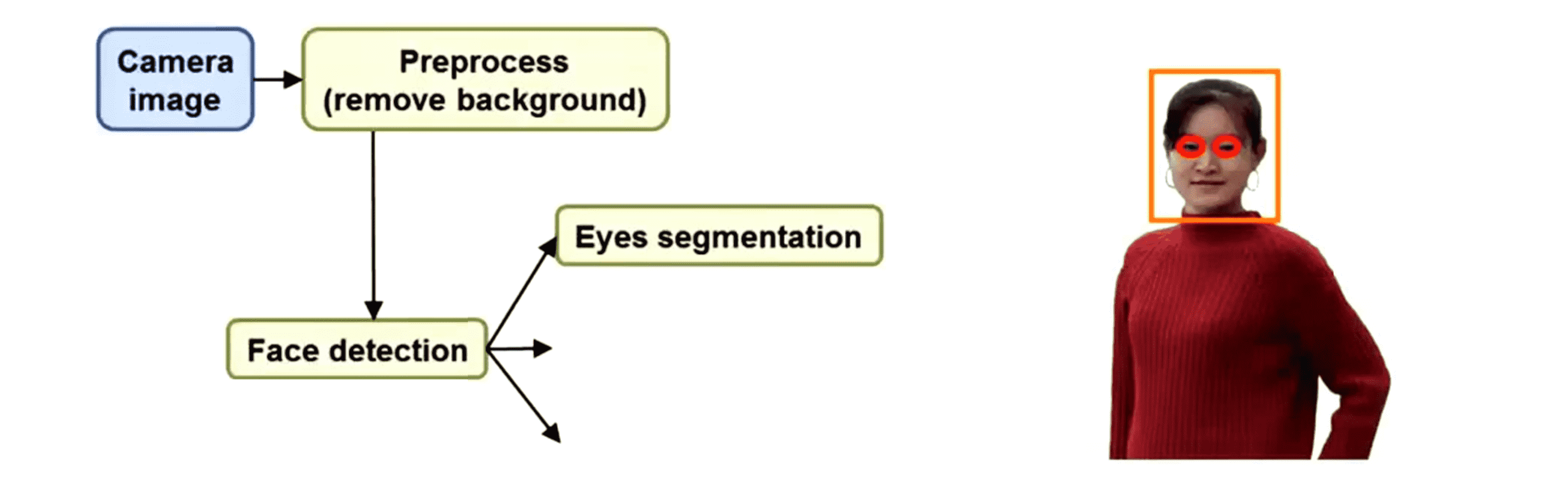
在检测到脸部以后如果我们想要识别出这个人那么眼睛是一个很重要的线索。事实上要辨认出朋友我们通常会看眼睛,这是个比较重要的线索。所以我们需要运行另一个分类器来检测人的眼睛分割出眼睛,这样就提供了识别出一个人的很重要的特征:
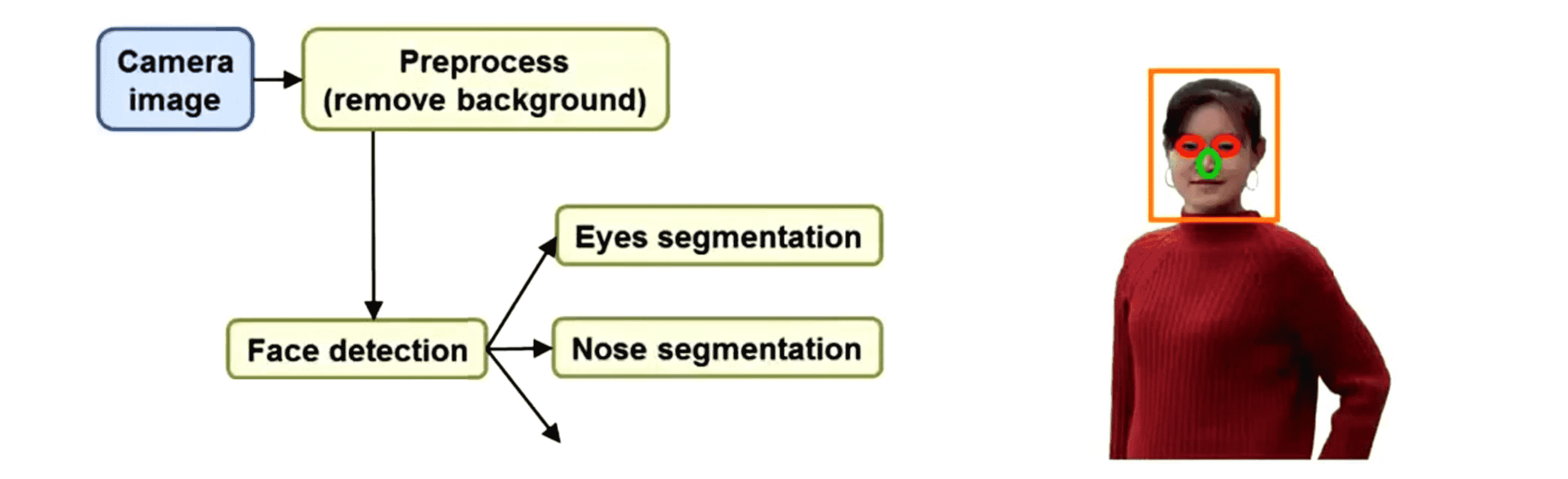
然后继续识别脸上其他重要的部位,比如分割出鼻子:
分割出嘴巴:
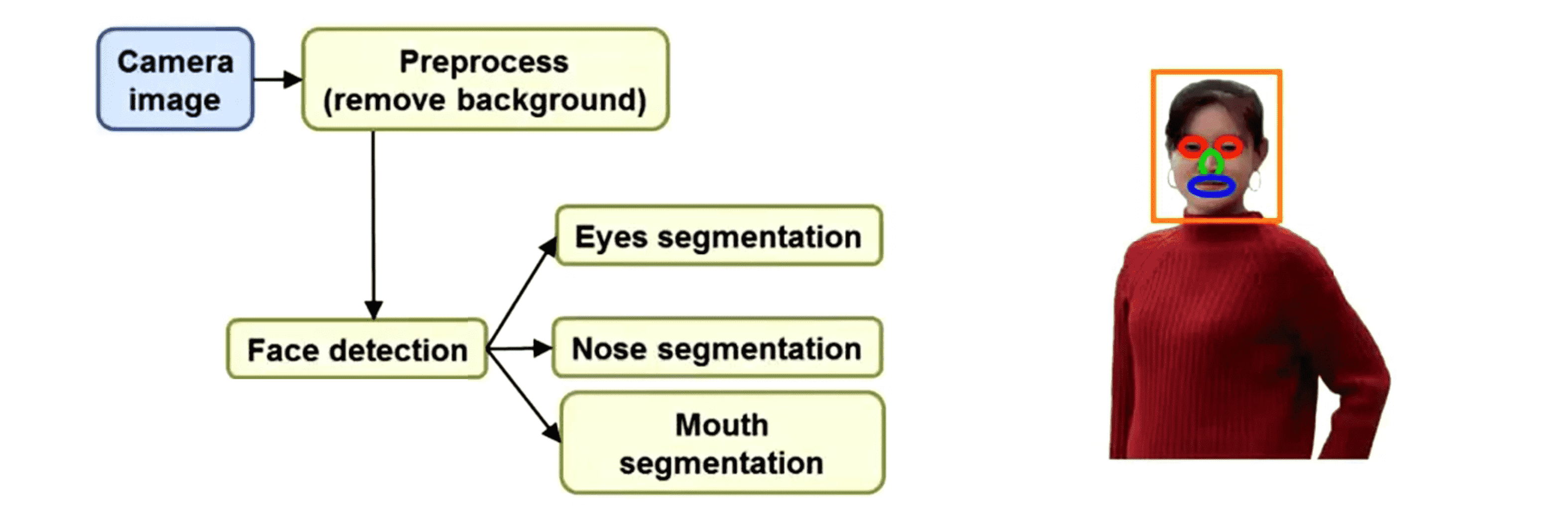
这样找出了眼睛、鼻子、嘴巴。所有这些都是非常有用的特征,然后这些特征可以被输入给某个逻辑回归的分类器,然后这个分类器的任务就是给出最终的标签找出我们认为能辨别出这个人是谁的最终的标签:
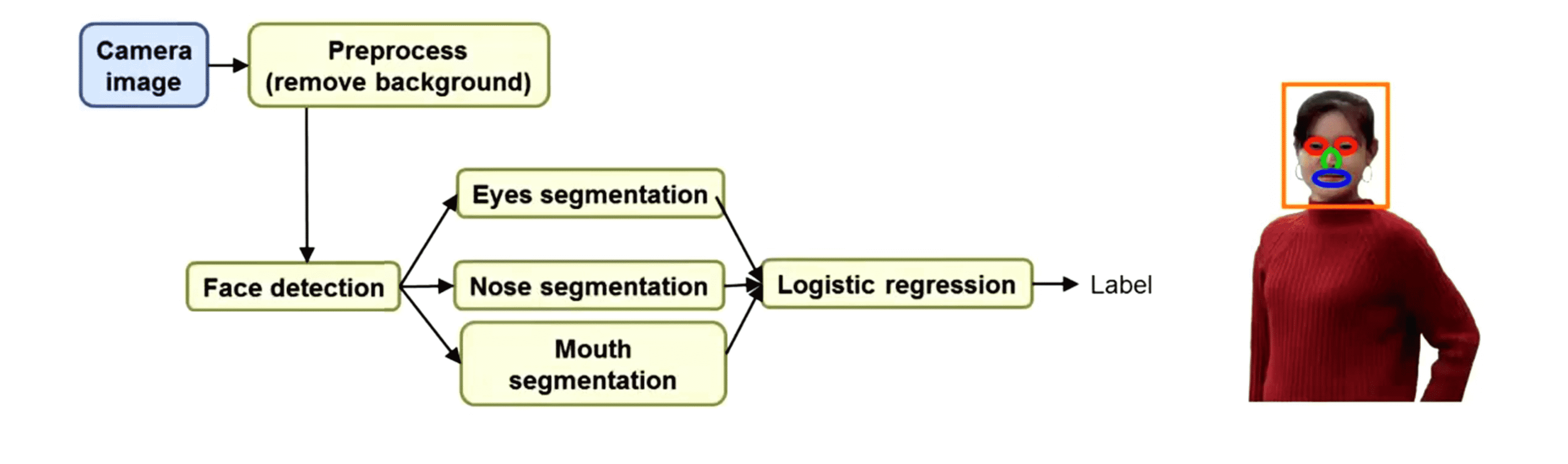
这是一个稍微复杂一些的流水线,如果我们真的想识别出人的话,可能实际的流程比这个还要复杂,但这给出了很好的一个上限分析的例子。那么对这个流水线怎么进行上限分析呢? 我们还是每次关注一个步骤:
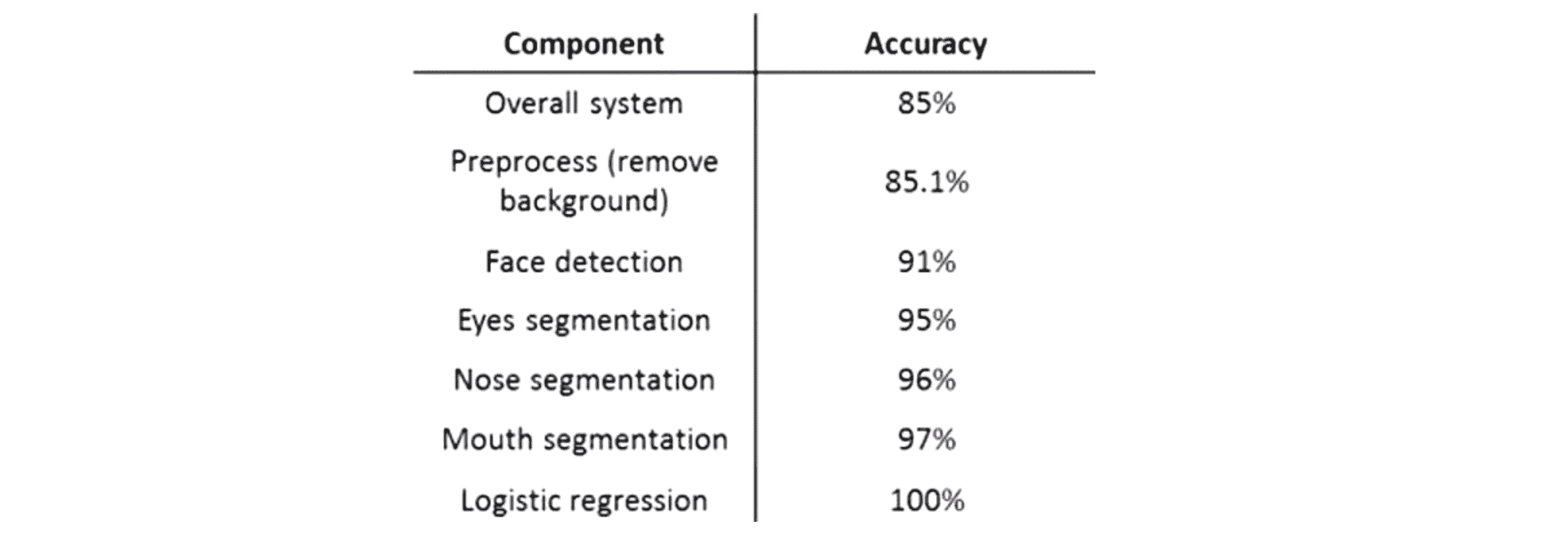
假如说你整个系统的准确率达到了85%,那么我要做的第一件事情还是找到我的测试集,然后对前景和背景进行分割,比如使用Photoshop或者别的什么软件识别出哪些区域是背景然后手动把背景删掉然后观察准确率提高多少,假设在这个例子中准确率提高了0.1%,这是个很明显的信号告诉我们即使把背景分割做得很好,就算完全去除了背景图案整个系统的表现也并不会提高多少。所以似乎并不值得花太多精力在预处理或者背景移除上。接下来再遍历测试集,给出正确的脸部识别图案,这时正确率道理91%。接下来还是依次运行眼睛、鼻子和嘴巴的分割,选择一种顺序就行了。比如给出眼睛的正确位置到了95%,鼻子的正确位置到了96%,嘴巴的正确位置到了97%。最后再给出最终的正确标签准确率提高到100%。
在我们每次通过这个系统的时候,随着使用有正确标签的测试集的模块越来越多,整个系统的表现逐步上升。这样我们就能很清楚地看到通过不同的步骤系统的表现增加了多少。比如有了完美的脸部识别整个系统的表现似乎提高了5.9% 这算是比较大的提高了;这告诉你也许在眼部检测上多做点努力是有意义的这里提高4%;鼻子和嘴巴检测这两步都是提高1%,最后的分类这一步提高3%。所以从整体上看最值得我们付出努力的模块按顺序排列一下,排在最前的是脸部检测,它让系统表现提高了 5.9%,给它完美的眼部分割系统表现提高4%,最终是我的逻辑回归分类器提高大约3%。因此这很清楚地指出了哪一个模块是最值得花精力去完善的。
顺便一提我还想讲一个真实的故事,我在预处理这里放入背景移除这个部分的原因是我知道一件真实的事情,原来有一个研究小组大概有两个人,不夸张地说他们花了一年半的时间整整18个月都在完善背景移除的效果,我不详细地讲具体的细节和原因是什么,但确实是有两个工程师为了开发某个计算机视觉的应用系统大概花了一年半的时间就为了得到一个更好的背景移除效果。事实上他们确实研究出了非常复杂的算法貌似最后还发表了一篇文章,但最终他们发现所有付出的这些劳动都不能给他们研发系统的整体表现带来比较大的提升而如果要是之前他们组某个人做一下上限分析,他们就会提前意识到这个问题。后来他们中有一个人说如果他们之前也做了某种这样的分析,他们就会在长达 18个月的辛苦劳动以前意识到这个问题,就可以把精力花在其他更重要的模块上,而不是把18个月花在背景移除上。
总结一下流水线是非常常用却又很复杂的机器学习应用,当我们在开发某个机器学习应用的时候作为一个开发者,我们的时间是相当宝贵的,所以真的不要花时间去做一些到头来没意义的事情。因此在这一部分,我们一同学习了天花板分析的概念。我经常觉得上限分析在判断应该改哪个模块上是个很有用的工具,当我们真的把精力花在那个模块上并且改进了它,它真的会让整个系统的表现有一个显著的提高。所以我们要慢慢养成不要凭自己的直觉来判断应该改进哪个模块,相反地如果要解决某个机器学习问题最好能把问题分成多个模块然后做一下天花板分析,这通常是一个更可靠更好的方法来为我们决定该把劲儿往哪儿使,该提高哪个模块的效果,这样我们就会非常确信把这个模块做好就能提高整个系统的最终表现。
结语
通过这篇BLOG,相信你已经了解了机器学习的流水线相关搭建方法了。虽然很不舍,但是我们机器学习的BLOG就要告一段落啦,接下来我们会回归到算法竞赛上来,为大家更新更多有趣实用的算法原理和实现。最后希望你喜欢这篇BLOG!


想问一下dalao的cloudreve是部署在哪里的呀(是blog所在的服务器还是另一个服务器
就是在Blog所在的服务器上呢