在上一篇BLOG中我们介绍了线性回归模型和代价函数,下面我们就来一同学习最小化代价函数的一种算法——梯度下降算法吧。
什么是梯度下降算法
我们先回顾一下我们的问题:

在这里,为了简化问题,我们有一个只关于两个参数的函数J(θ0, θ1),它可以是一个线性回归的代价函数,也可以是一些其他函数,我们的目标是要使其最小化,这时我们就可以用到我们的梯度下降算法。
我们要做的是,随机初始化定义一个θ0和θ1(也可直接θ0设为0,将θ1也设为0。我们在梯度下降算法中要做的就是不停地一点点地改变θ0和θ1,试图通过这种改变使得J(θ0, θ1)不断变小,直到我们找到 J 的最小值——一个局部最小值。下面让我们通过一个例子来看看梯度下降法是如何工作的:
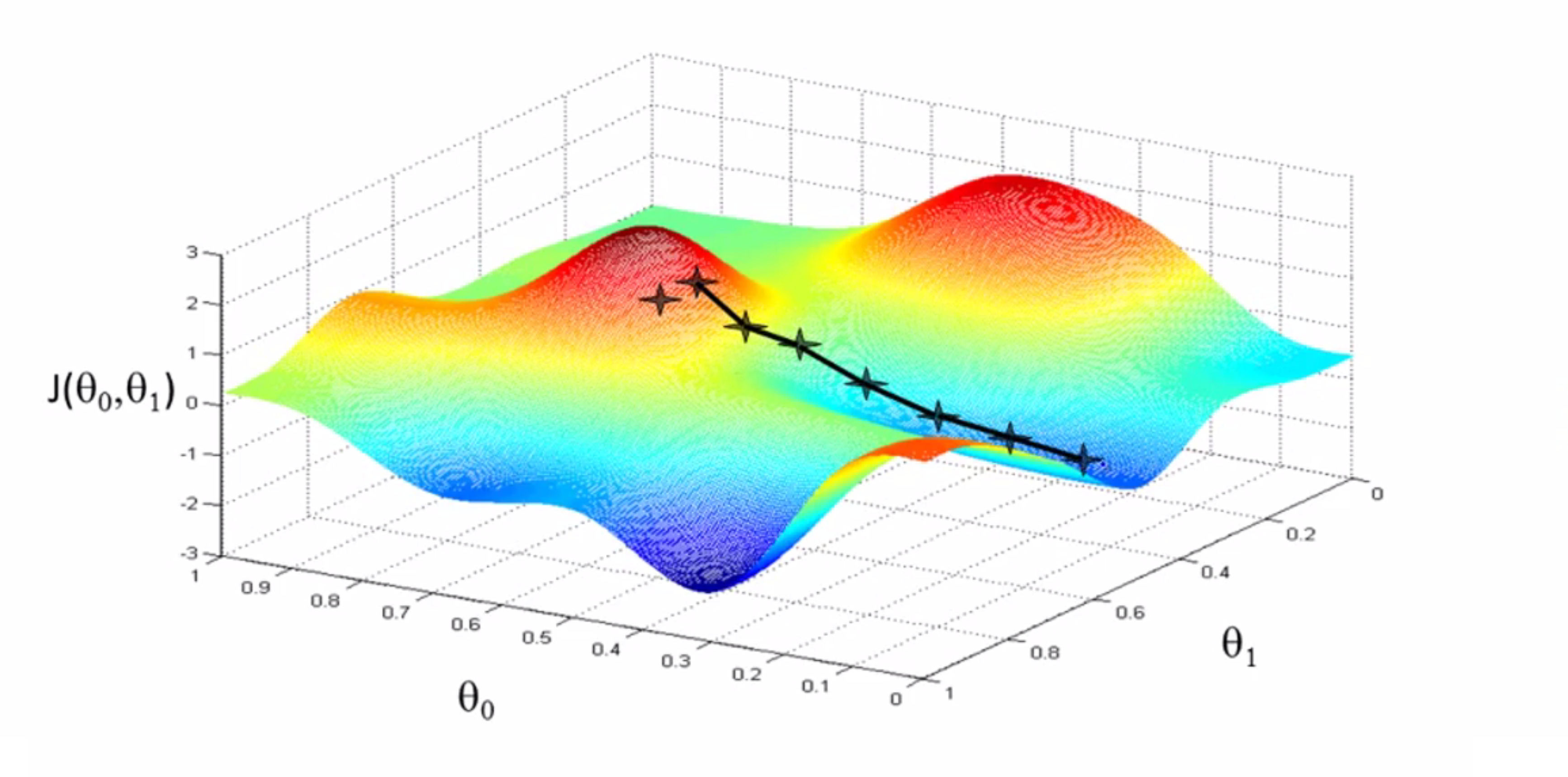
我们先假设我们的代价函数 J 如下所示,我在试图找到这个函数值最小时对应的θ0和θ1,注意坐标轴θ0和θ1在水平轴上 而函数 J 在垂直坐标轴上,图形表面高度即是 J 的值:
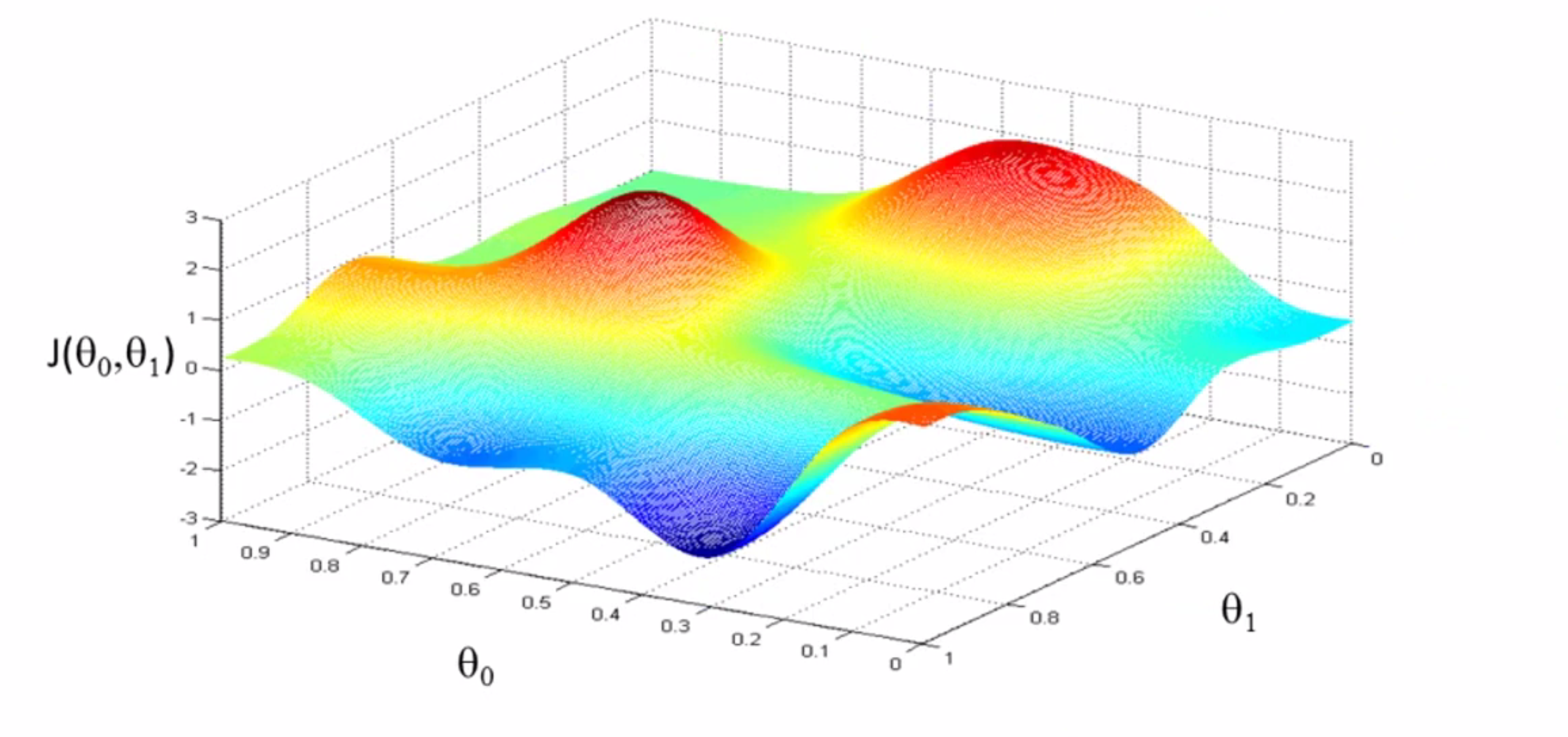
所以我们从某个θ0和θ1出发,一步一步走向最低点。我们可以把这个图像想象为公园里的两座山,你正站立在山的这一点上,在梯度下降算法中,我们要做的就是在你所站的点上,旋转360度,看看我们的周围并问自己要在哪个方向上用小碎步行走才能尽快下山?
我们看一下下面这个例子,如果我们站在山坡上的打星的这一点:
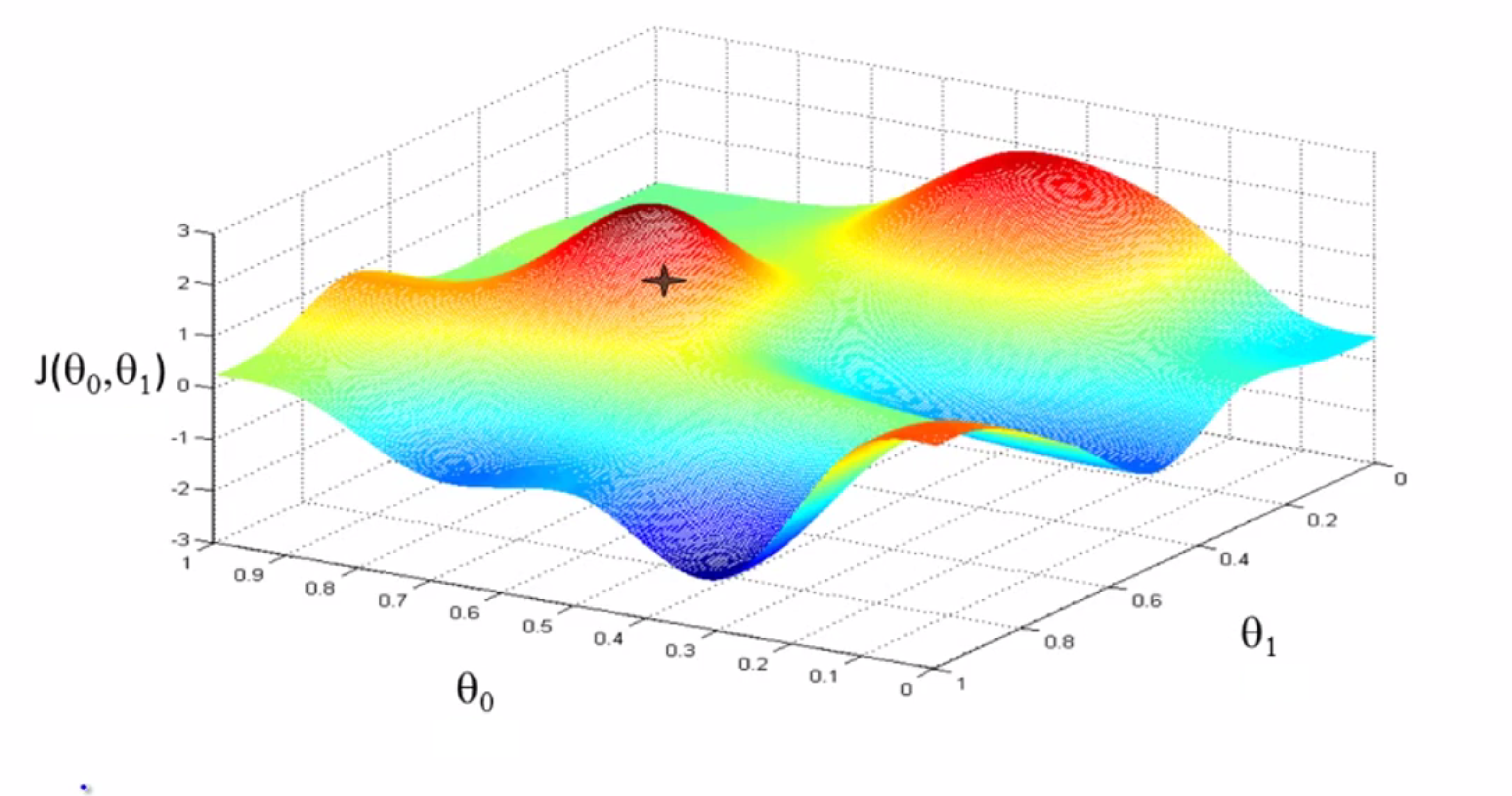
然后你环顾了一下周围,发现了最佳的下山方向,大约是往右下角的方向,你往那迈出了一步:
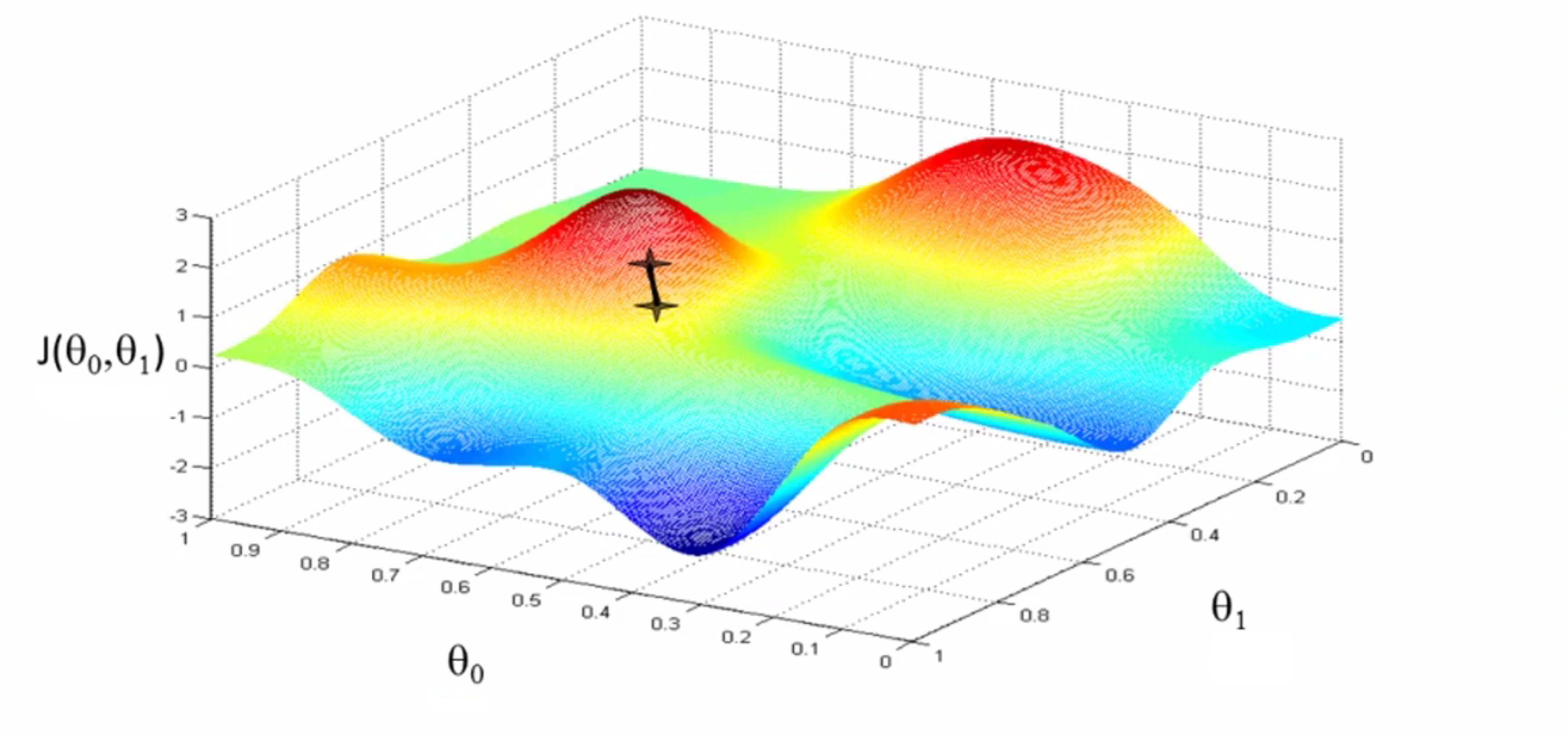
现在你在山上的新起点上,你再看看周围,然后再一次想想应该从什么方向迈着小碎步下山……依此类推,直到你接近这个局部最低点的位置——也就是山谷:
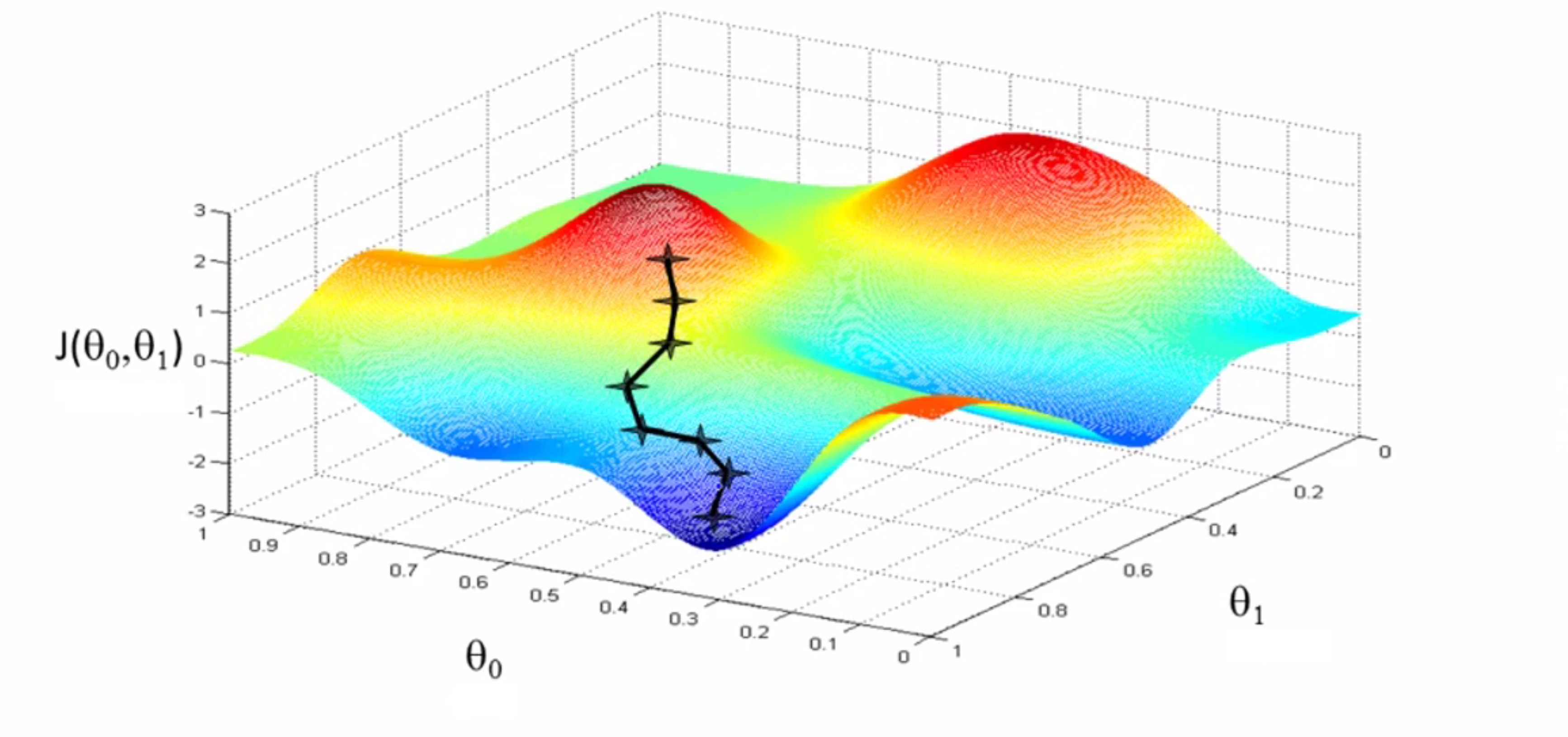
不知道你有没有发现,这种下降有一个有趣的特点,如果我们在刚才的右边一些的位置开始进行梯度下降,我们重复上述步骤,梯度下降算法将会带你来到,这个右边的山谷,而不是刚刚的那个山谷了,这就是梯度下降的一个有趣的特点:
相信通过上面的例子你已经对梯度下降算法有了直观的感受,下面我们就来对梯度下降算法进行严格定义:
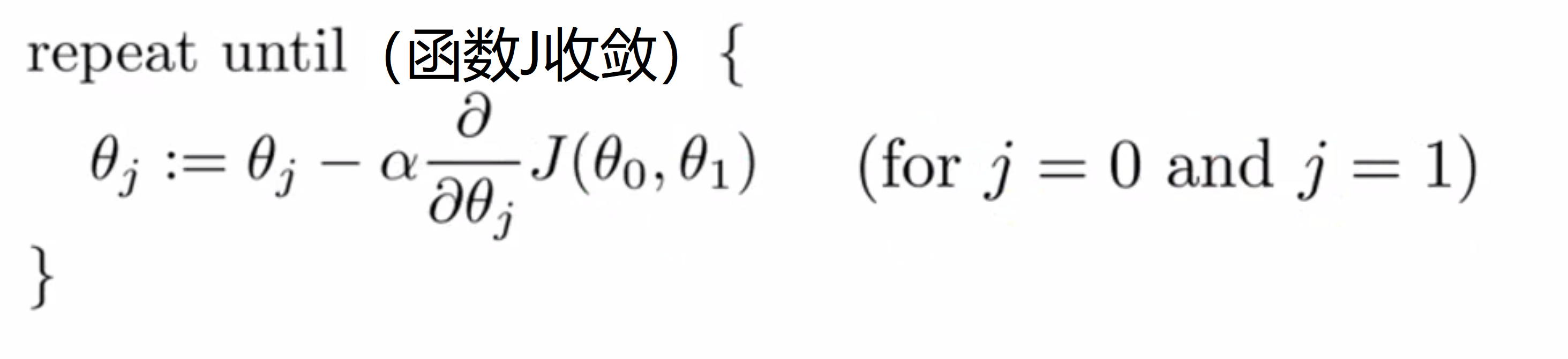
看这个repeat语句,我们将会反复执行括号里的内容直到收敛。我们要更新参数 θj 方法是 用 θj 减去 α乘以一个偏导数也就是微分,这里的 α 是一个数字,被称为学习速率,在梯度下降算法中它控制了我们下山时会迈出的步子有多大,α越大我们每一步迈出的步子也越大。
接着我们来看公式的最后一部分,也就是紫色框框里的这部分:

这是一个微分项,如果你不熟悉微分也没关系,我们将在下一part详细讨论它。
最后有必要提一下算法实现方面的问题,在每次梯度下降的时候我们都要依次更新 θj , 这时我们在做法应该是用一个 tempj 先存储好更新后的 θj 的值, 等所有 temp 的值都计算好后,再一同将 tempj 赋值到 θj :

如果计算一个赋值一个,如右边那个一样,就会在 temp1的计算中,使用到已经更新的 θ0 ,计算出不太正确的答案。
梯度下降算法公式
我们先来回顾一下我们梯度下降的转移公式:
我们这部分就是要让你更直观的认识 α这个学习速率和后面这个微分项这两部分的具体含义。
为了让整个过程更加直观,我们将问题简化一下,假如我们有一个代价函数 J 只有一个参数 θ1,那么我们可以画出一个 J 关于 θ1 的函数图像,大概如下所示:
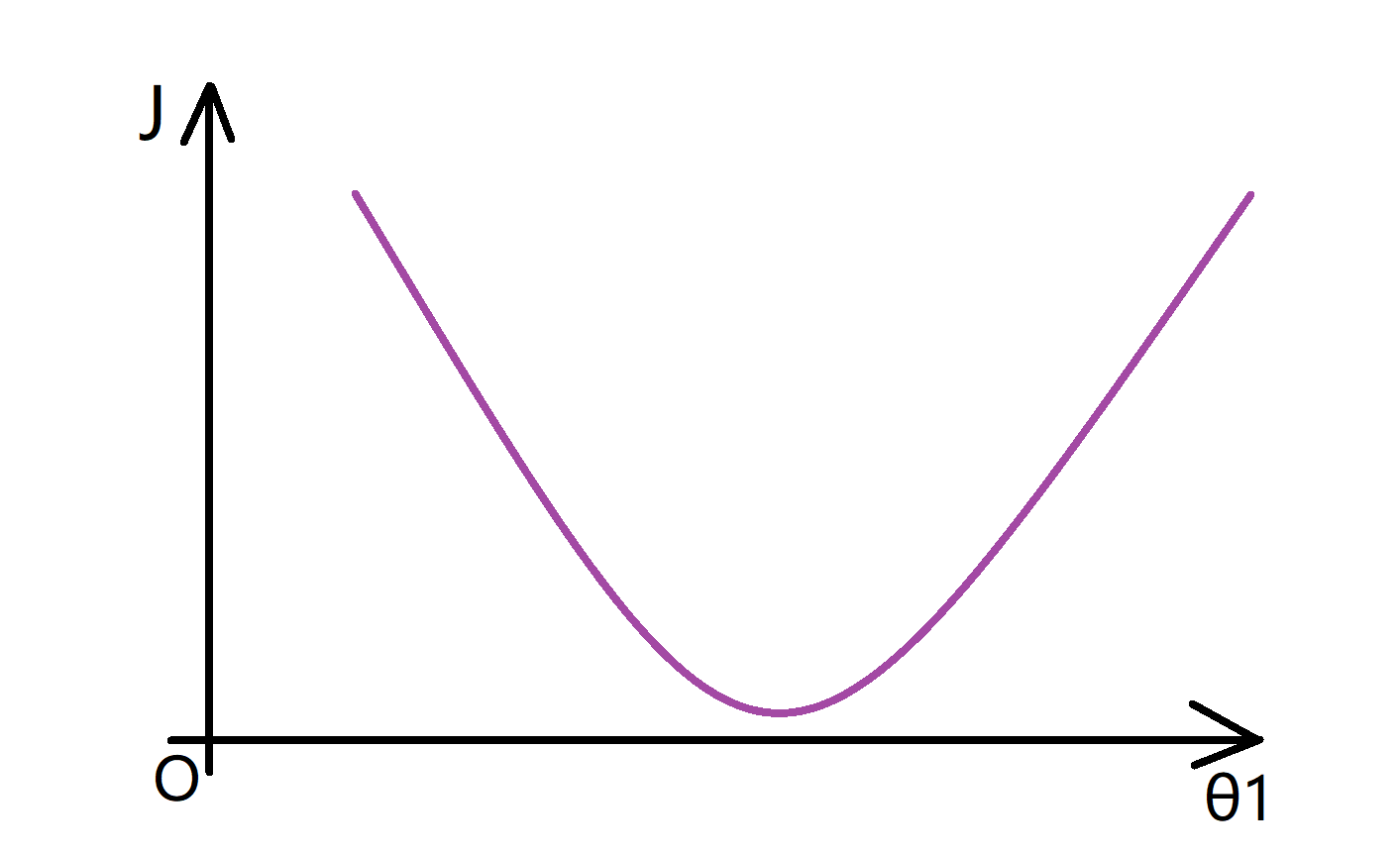
微分项
这个图像看起来很简单,让我们试着去理解为什么梯度下降法能帮助我们找到最小值吧。想象一下我们先选定了一个X点作为我们的初始点:
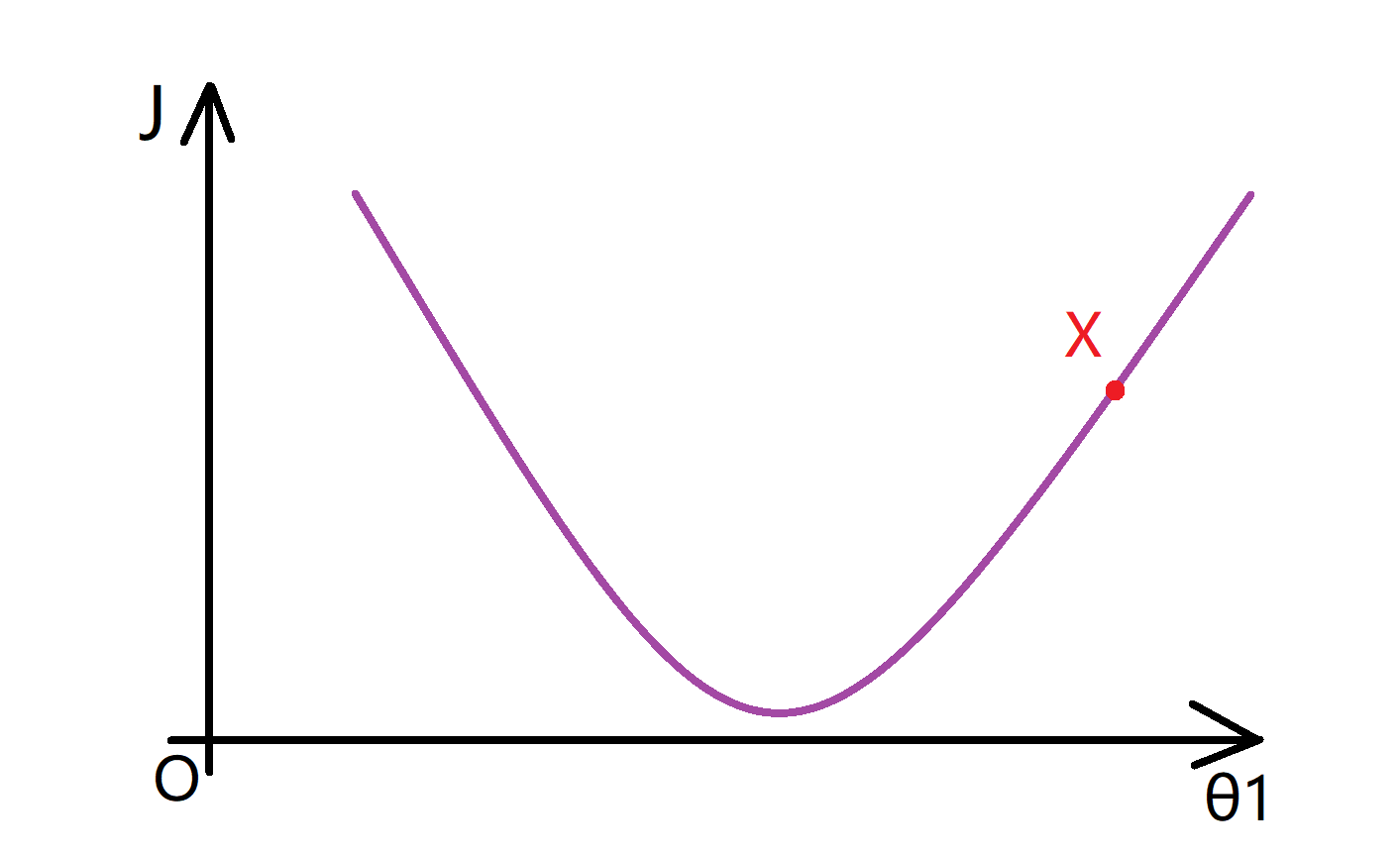
那么梯度下降要做的事情是不断更新 θ1 = θ1 - α d(J(θ1))/d(θ1) 这个项(PS 如果你不知道原公式中的偏导数的符号 ∂/∂θ 和导数符号 d/dθ 之间的区别是什么,请不用担心 ,偏导数还是导数,这取决于函数J的参数数量,但是这是一个数学上的区别,在实现中可以默认为这些偏导数符号和d/dθ1是完全一样的东西)。我们要计算 这个导数,就是要取这一点的切线(如下图蓝色直线),而这条蓝色直线的斜率就是这个点的导数值:
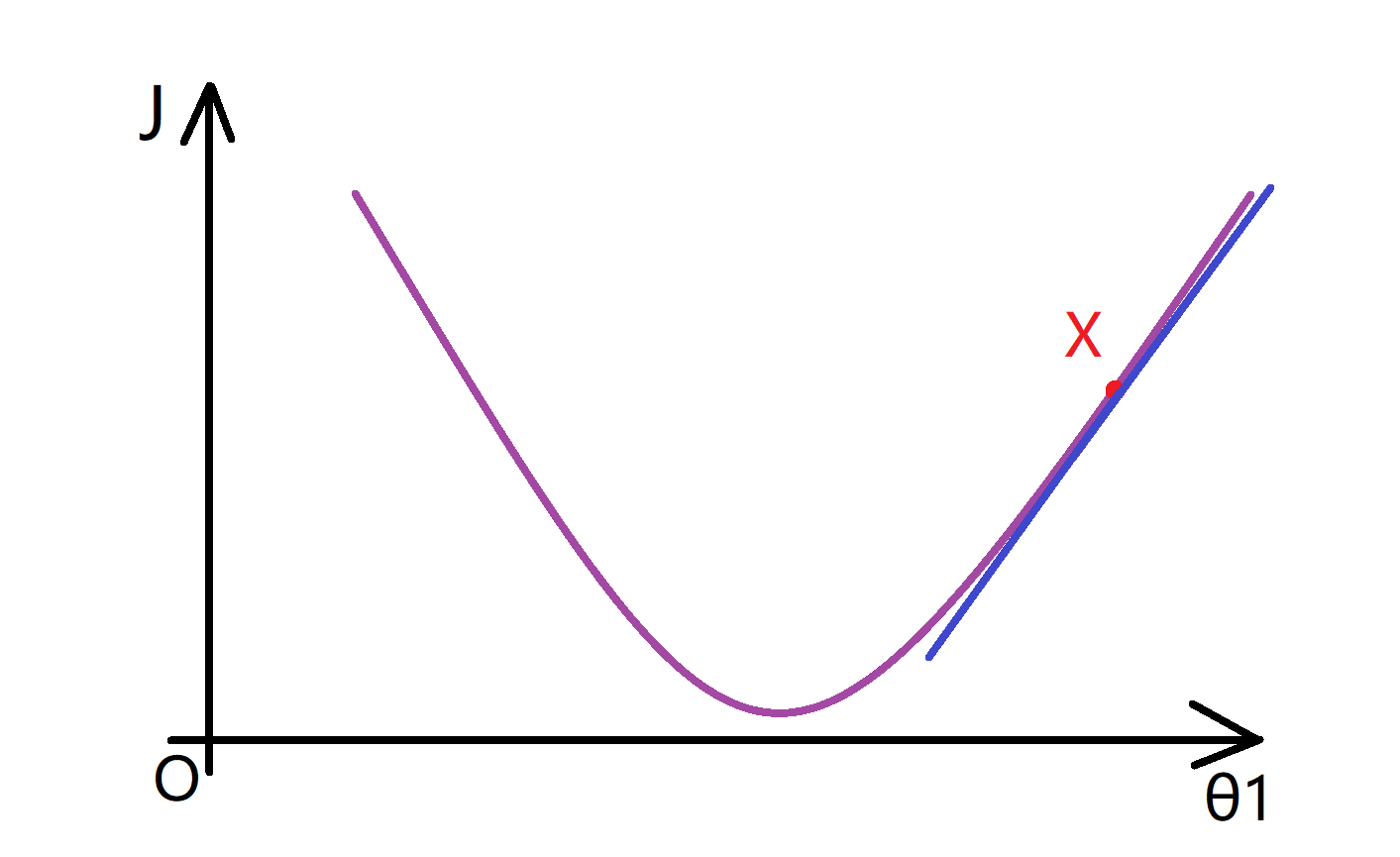
现在我们看到这条线的斜率是正数,也就是它的导数也是正数,因此我得到的新的θ1=θ1-一个正数*α。α 也就是学习速率也是一个正数,所以我要使θ1减去一个正的东西,所以相当于我将θ1向左移,从X点移动到Y点,使θ1变小了:
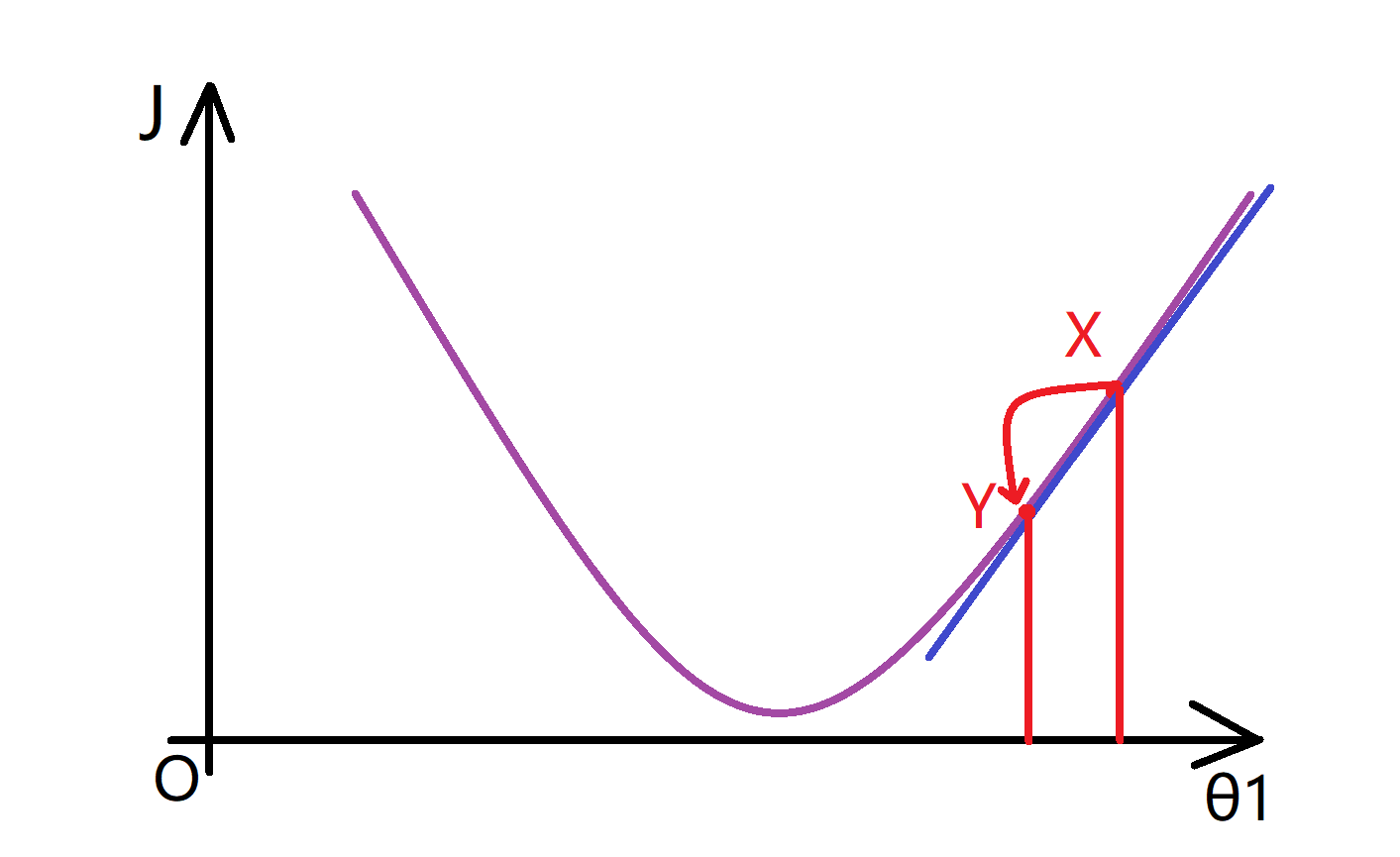
我们可以看到,这么做是对的,因为实际上我往这个方向移动,确实让我更接近那边的最低点。所以梯度下降在左移上好像是正确的。
那右移是否也一样能够正确呢?让我们来看看另一个例子,我们用同样的函数J,同样再画出函数J(θ1)的图像:
而这次,我们把初始化的点X放到左边,现在对于导数d(J(θ1))/dθ1的计算,我们发现过这个点的切线向下倾斜斜率是负的(如蓝线所示):
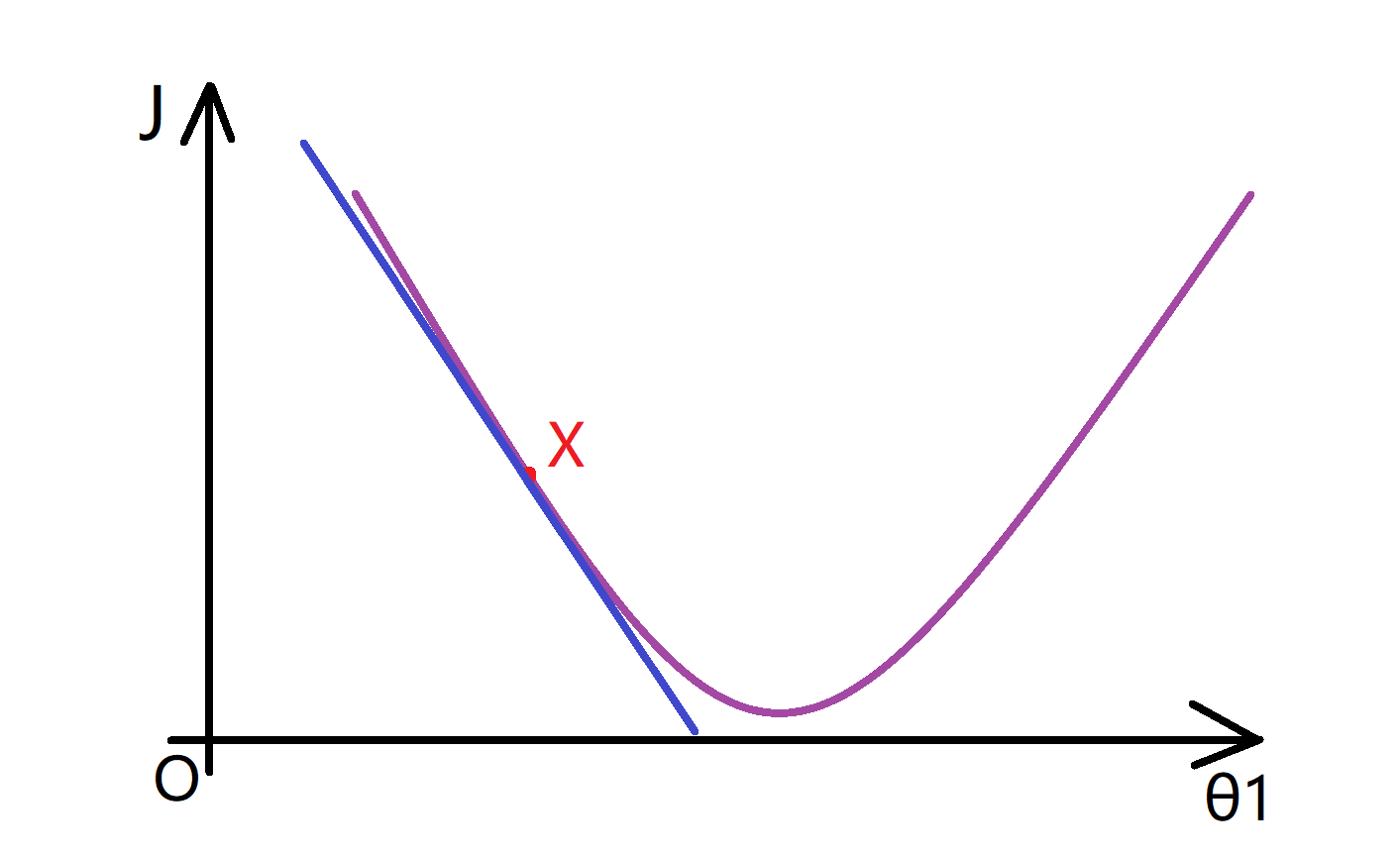
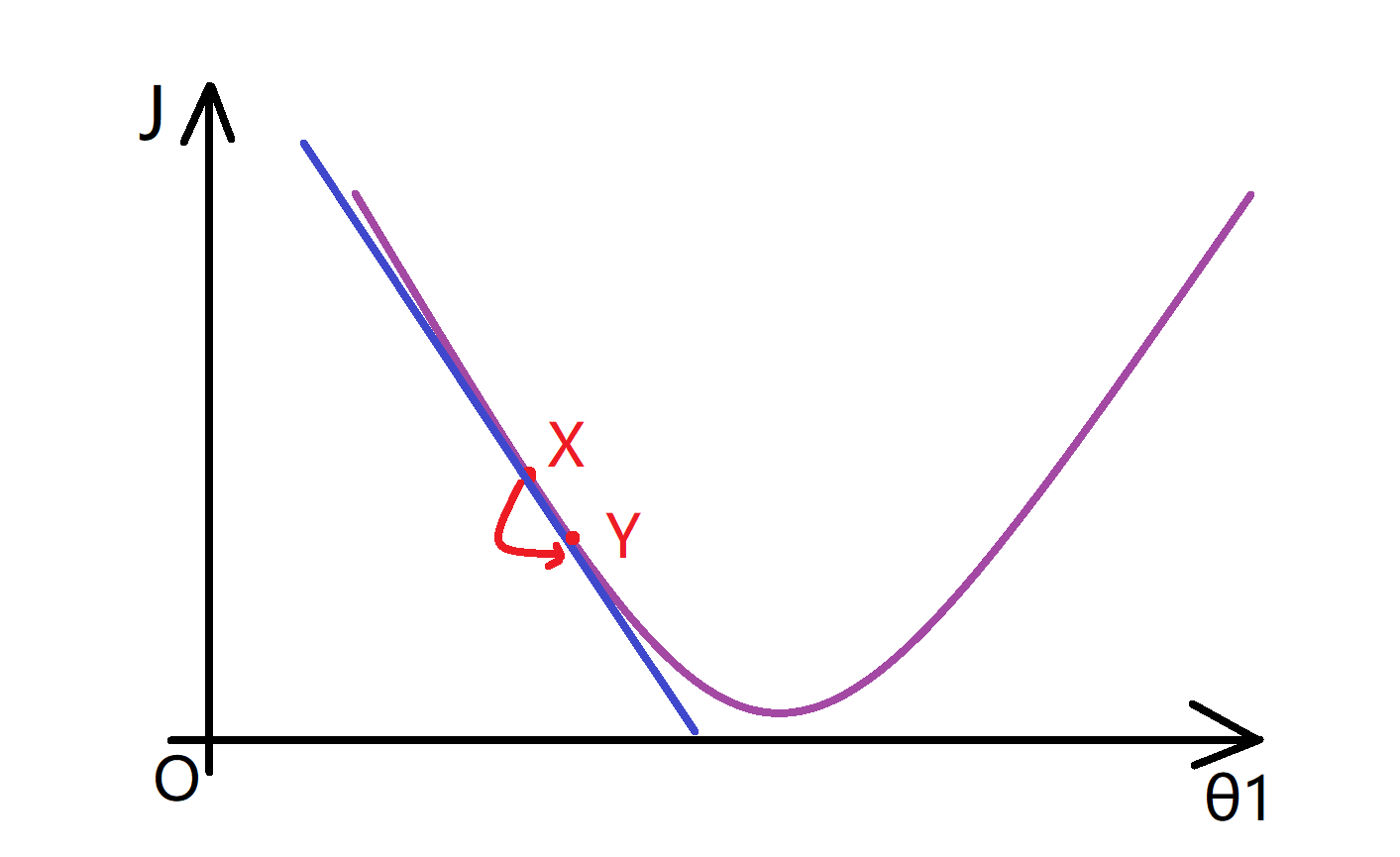
所以说这个点的导数值也是负的,所以,当我更新θ1时,θ1被更新为θ1减去α乘以一个负数,这意味着我实际上是在增加θ1的值,使其向右移动。这也让我们更接近最小值了,相信通过这两个例子你已经初步理解微分项的含义了:
学习速率α
让我们接下来再看一看学习速率α,让我们来看看如果α 太小或 α 太大会出现什么情况。
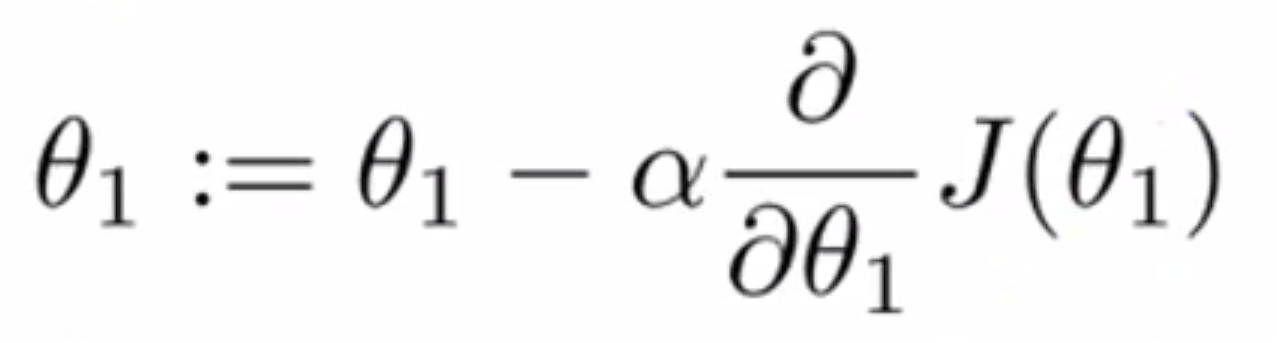
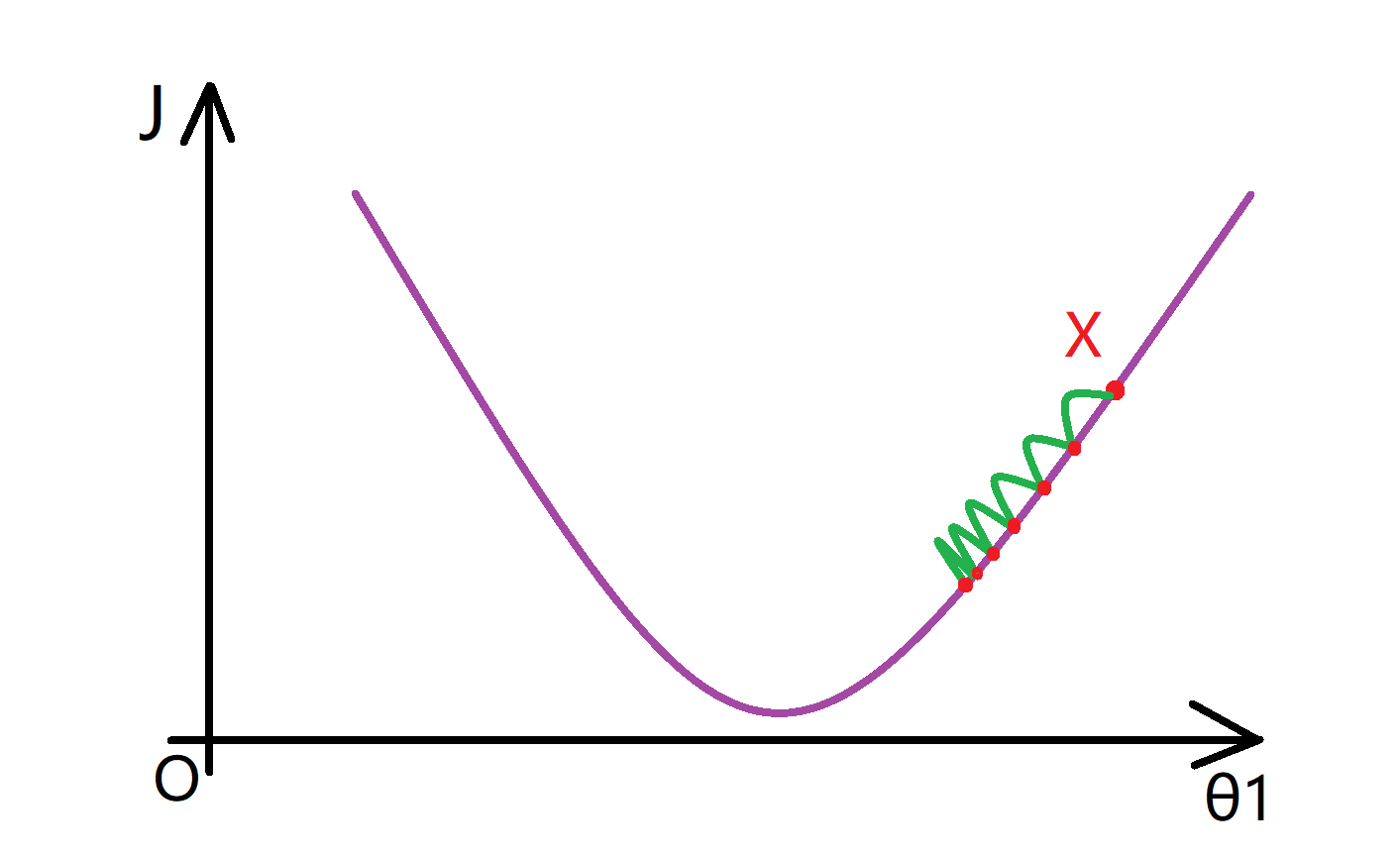
我们下先来看看如果α太小会发生什么呢。下面是函数J(θ),我们假设整个过程从X点开始。如果α太小了,那么我要做的是要去用一个比较小的数乘以更新的值,每一步都迈的很小,这样就需要很多步才能到达最低点,让时间效率大大降低:
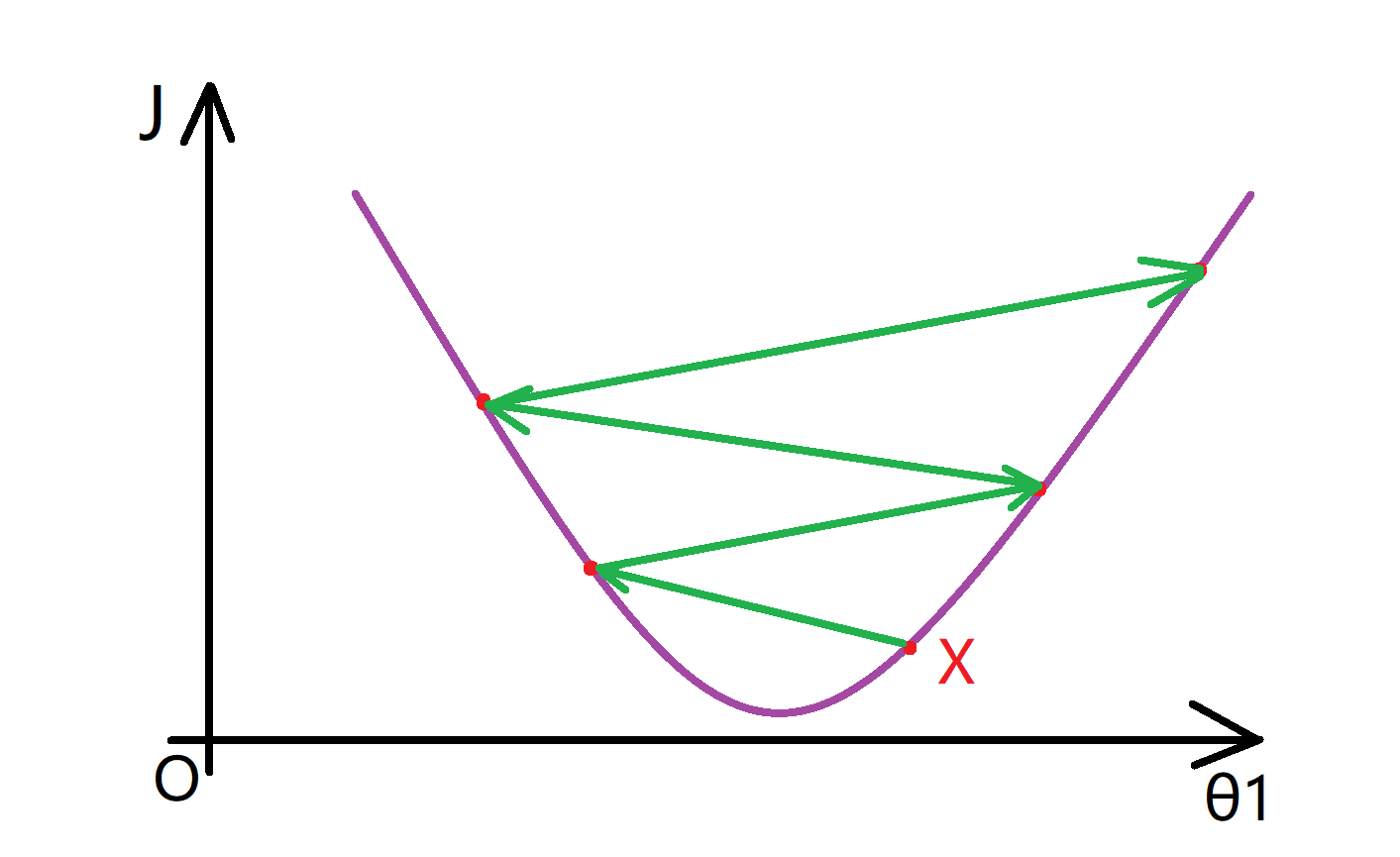
而如果 α 太大又会怎样呢?下面还是函数J(θ),如果 α 太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,也就是说,如果α 太大的话,就算迈的方向是对的,迈出很大一步后也可能让我们的结果变得更糟,甚至离这个最低点越来越远:
现在还有一个挺有趣的问题,如果我们预先把θ1,放在一个局部的最低点,你认为下一步梯度下降法会怎样工作?假设我们将θ1初始化在局部最低点,我们发现这个点的导数等于零,因为其切线的斜率等于零,而θ1 = θ1 - α * 0。这意味着如果你已经在局部最优点,梯度下降算法将使得θ1不再改变,也就是新的θ1等于原来的θ1,这也正是我们想要的。
在大多数情况下,我们的J函数都是下凸函数,所以在梯度下降法中,当我们接近局部最低点时,斜率的绝对值会不断变小,下降的幅度也越来越小,也能能好地逼近我们的最小值:
利用梯度下降解决线性回归问题
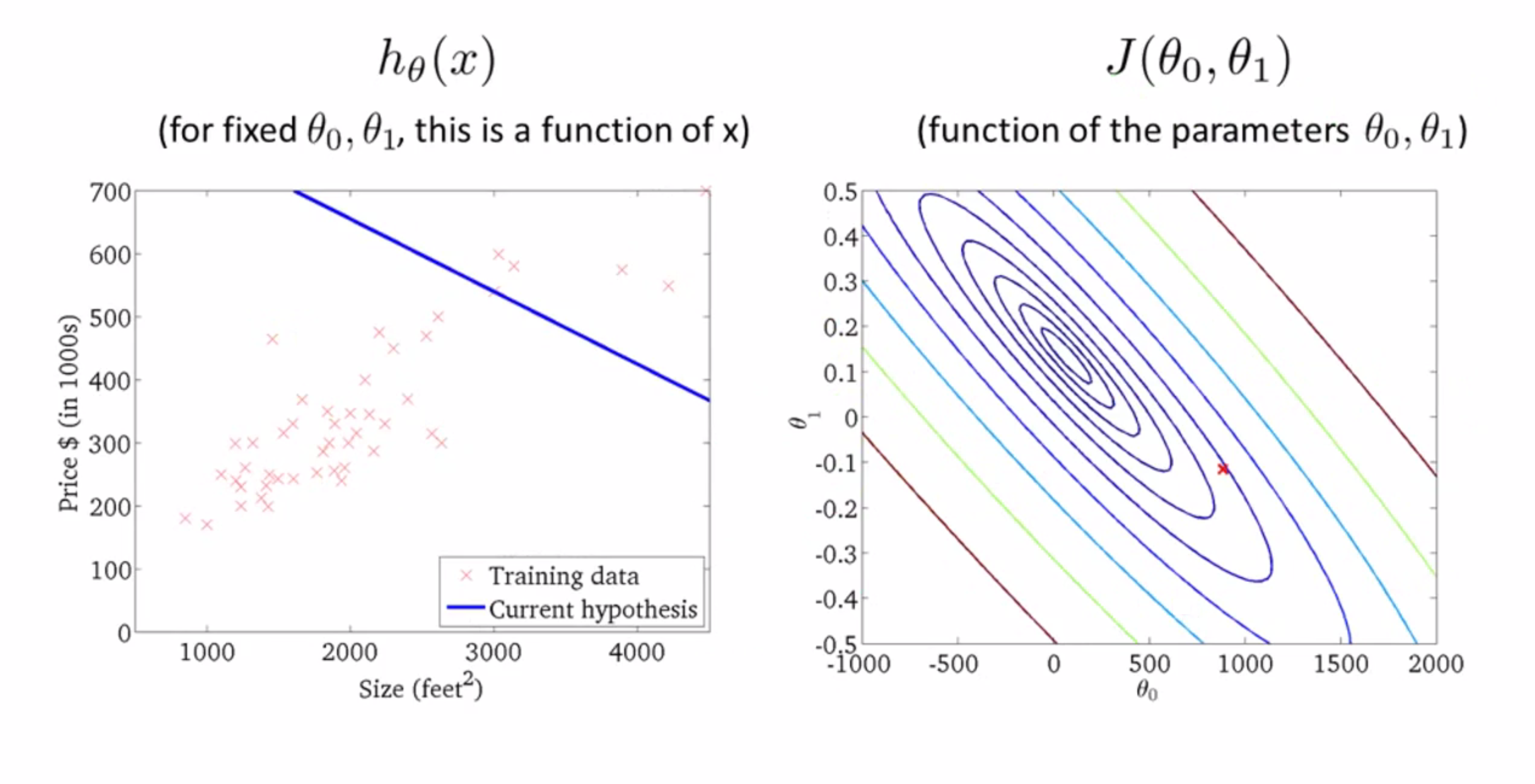
刚刚我们已经详细学习过了梯度下降算法,现在我们要梯度下降算法和代价函数结合,运用在线性回归问题当中。我们回顾一下,下图中左边梯度下降法,右边是线性回归模型还有线性假设和平方误差代价函数:

我们将要做的就是用梯度下降的方法来最小化平方误差代价函数。现在我们代码实现的难点就是这个微分项,所以我们需要弄清楚这个偏导数项在代价函数中具体是什么。
我们看一下这个微分式展开一下就是下图:
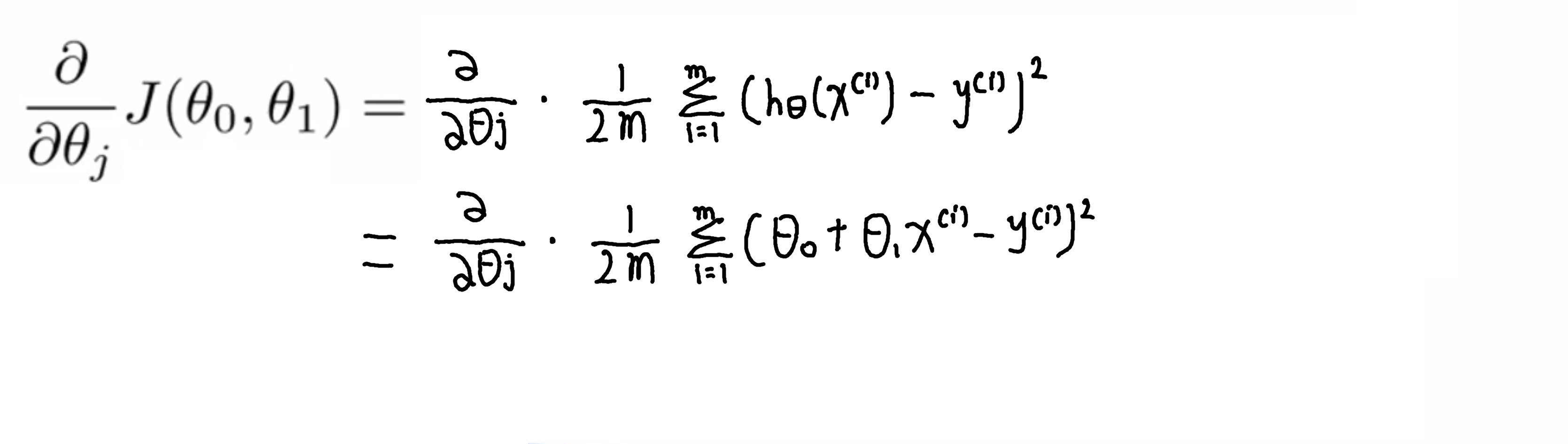
要弄清偏导数是什么,其实我们也只要弄清楚j=0 和j=1的情况就可以了,因此我们要弄清楚 θ0 和 θ1对应的偏导数项的表达式是什么,其实答案就如下所示:
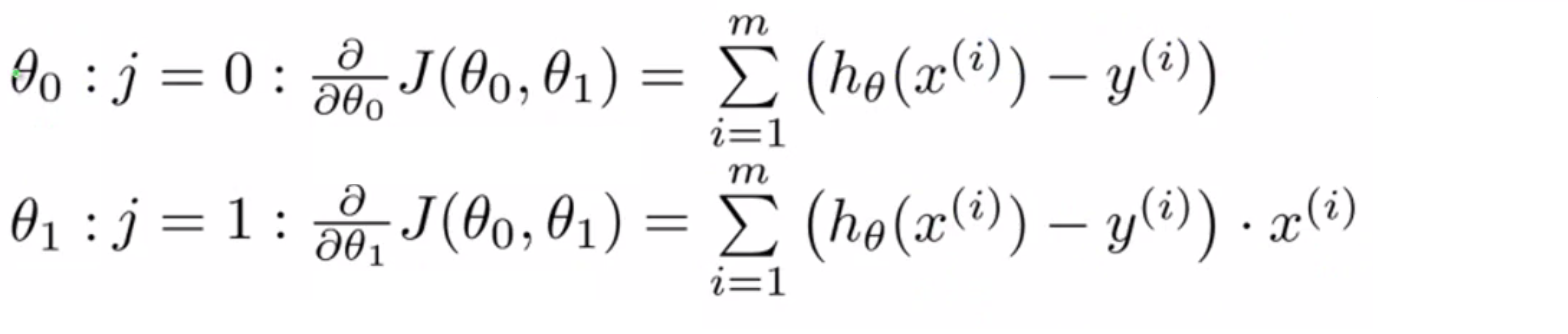
计算这些偏导数项需要一些多元微积分。如果你掌握了微积分,你可以随便自己推导这些;但如果你不太熟悉微积分,也别担心,你可以直接用这些已经算出来的结果。
所以这就是专用于线性回归的梯度下降中,我们要反复执行括号中的式子直到收敛,θ0和θ1不断被更新:
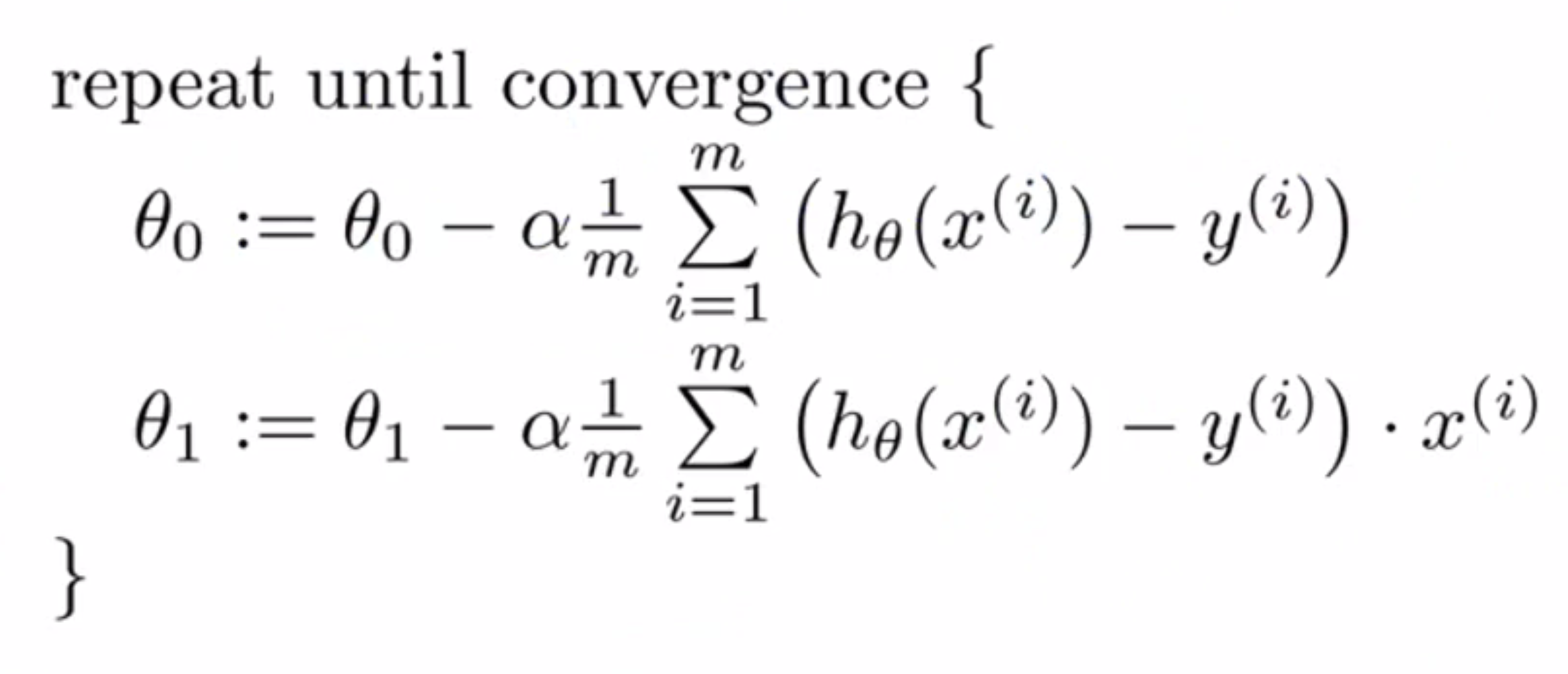
然后提醒一下,执行梯度下降时,有一个细节要注意,就是必须要同时更新θ0和θ1。
最后让我们来看看梯度下降具体是如何工作的。当我门第一次接触梯度下降时,我展示过这幅图:
我们的初始化点会在梯度下降算法的作用下不断逼近局部最优点,而不同初始点的选择可能会得到不同的局部最优解。但事实证明用于线性回归的代价函数总是下图这样一个弓形的样子,也就是一个凸函数:
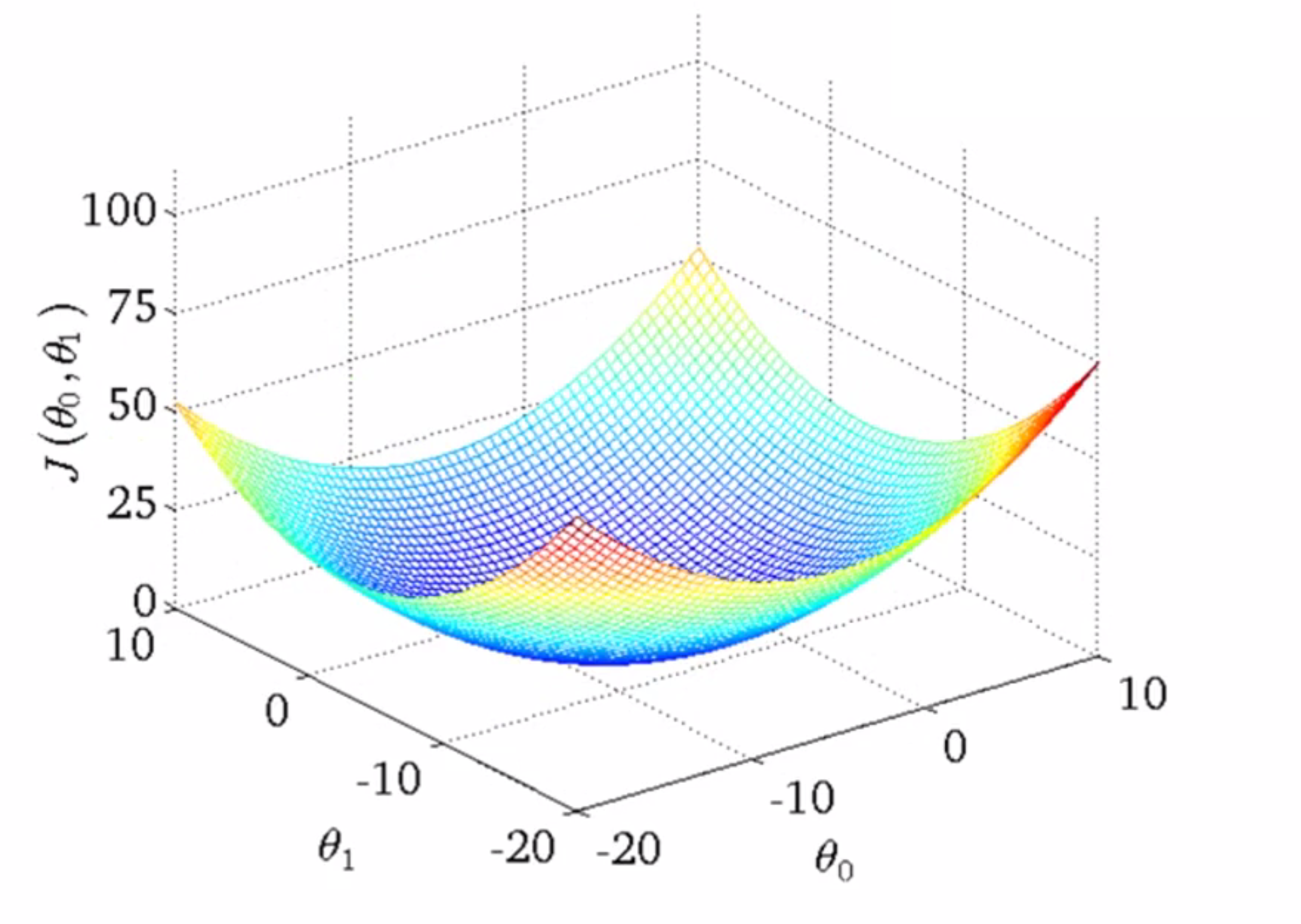
这个函数,没有任何局部最优解,只有一个全局最优解,所以无论什么时候,你对这种代价函数使用线性回归,梯度下降法得到的结果总是收敛到全局最优值,因为没有全局最优以外的其他局部最优点的存在。
现在让我们来具体看看这个算法的执行过程,还是卖房子的问题,我们首先吧θ0初始化为-900,θ1初始化为-0.1,所得到的直线和得到的J值如下所示:
现在,如果我们迈出一步,我们将到达那边的第二个点,其代表的左边的直线也会变,我们也得到了新的代价函数:
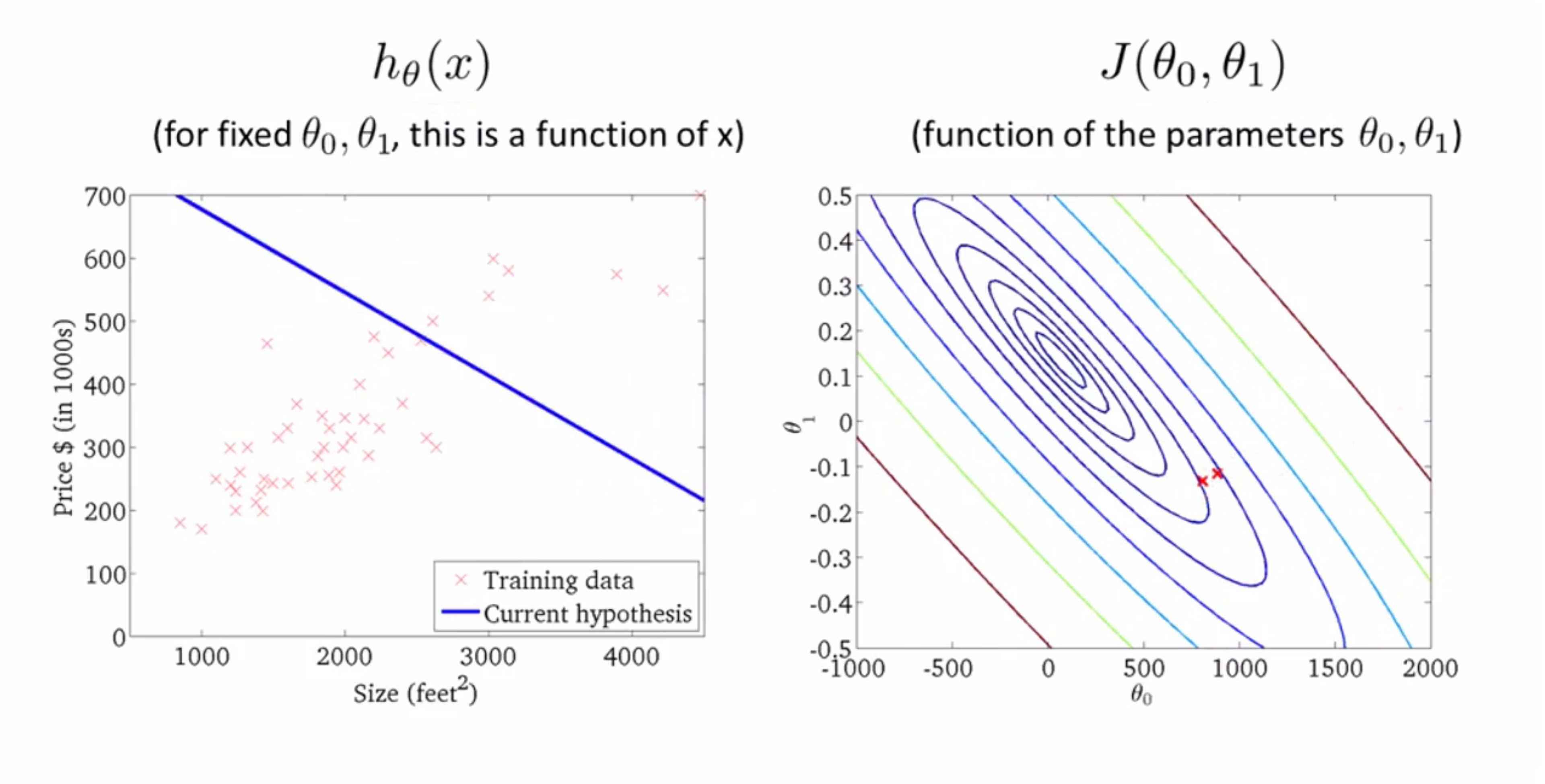
当我采取进一步的梯度下降,我要让J尽快下降,所以我的参数是沿着下图中类似山脊的轨迹下降的,这时你再看看左图,似乎越来越好了:
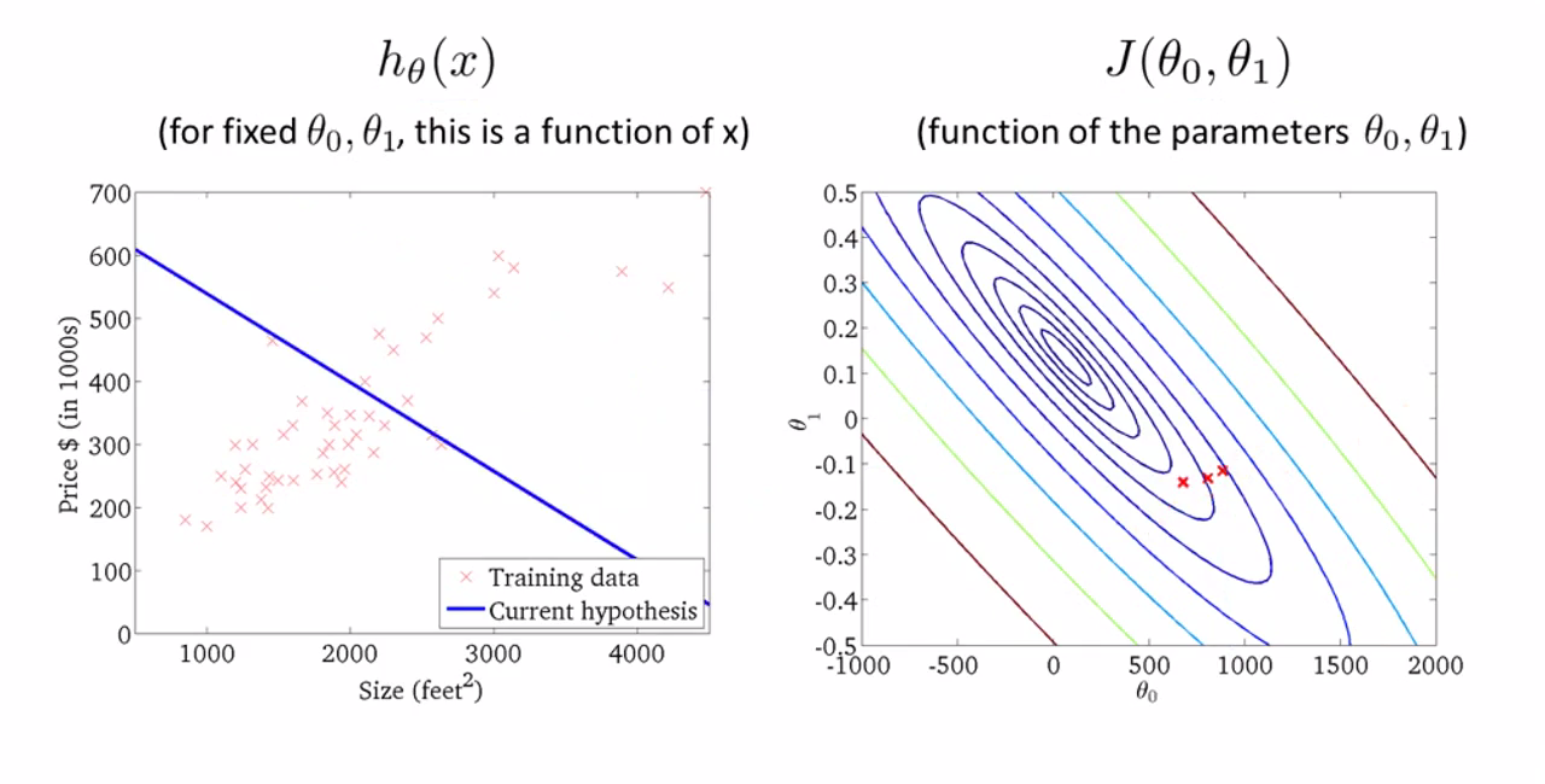
再下降一步:
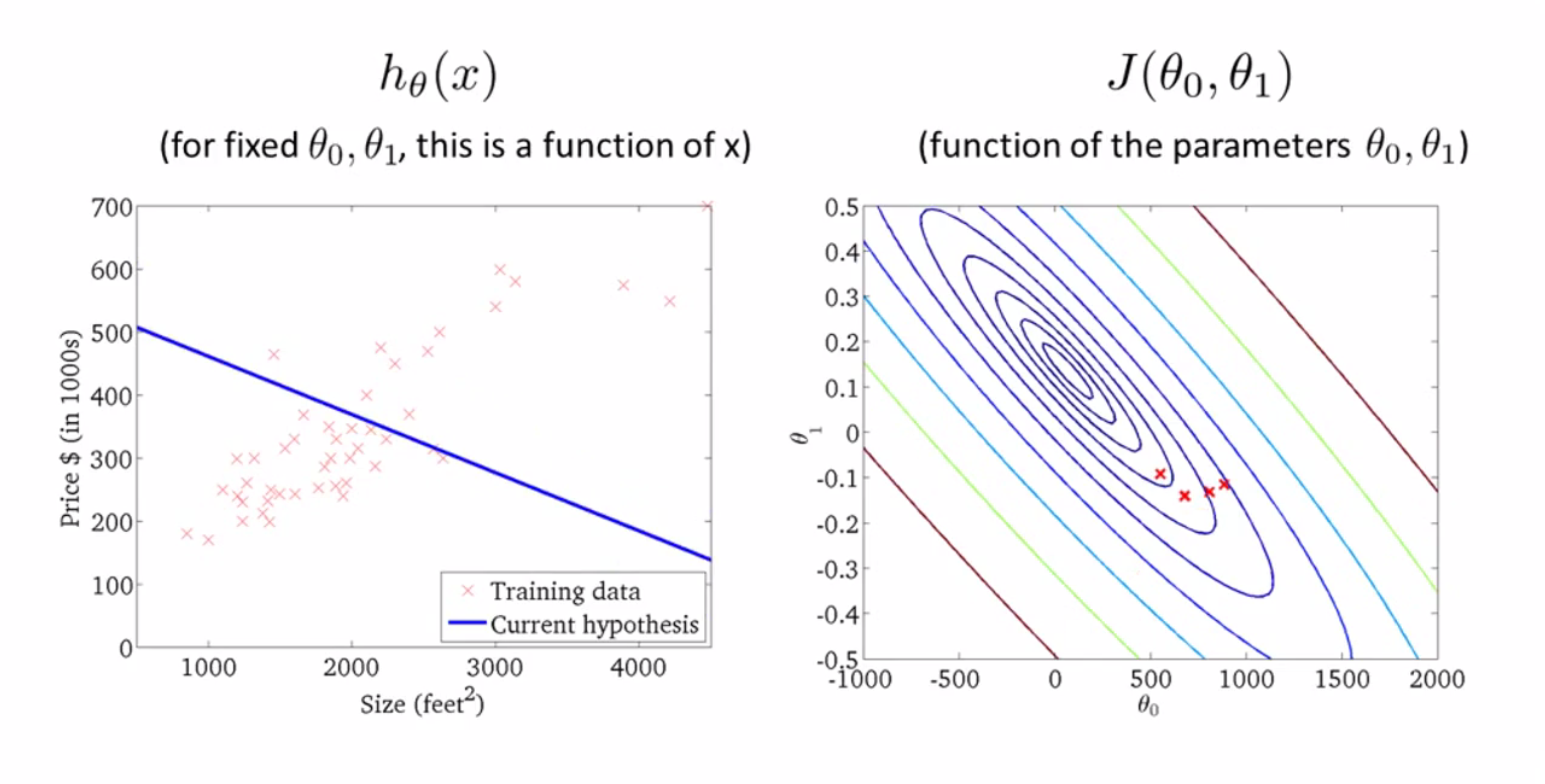
再来一步:
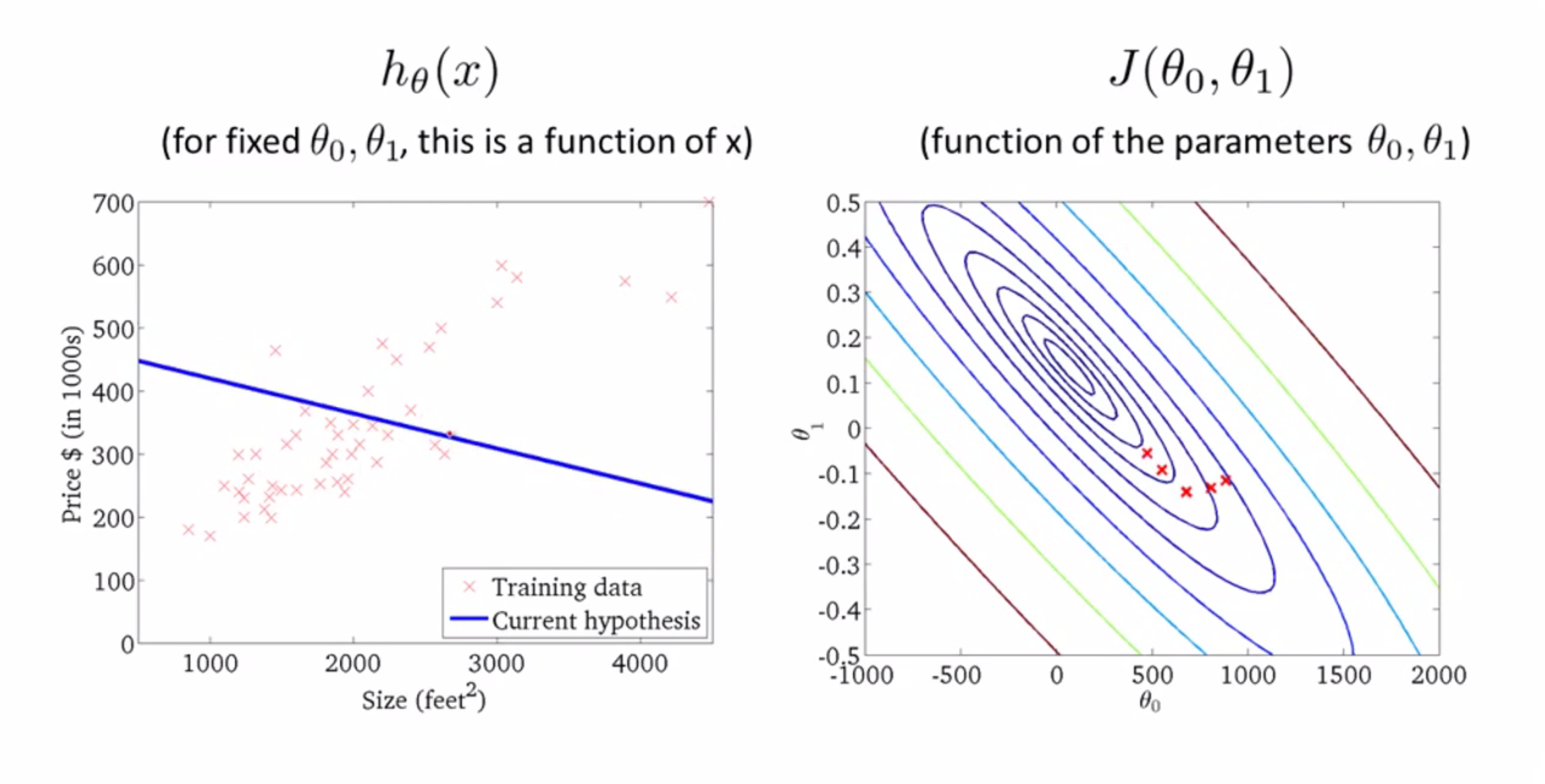
再来一步:
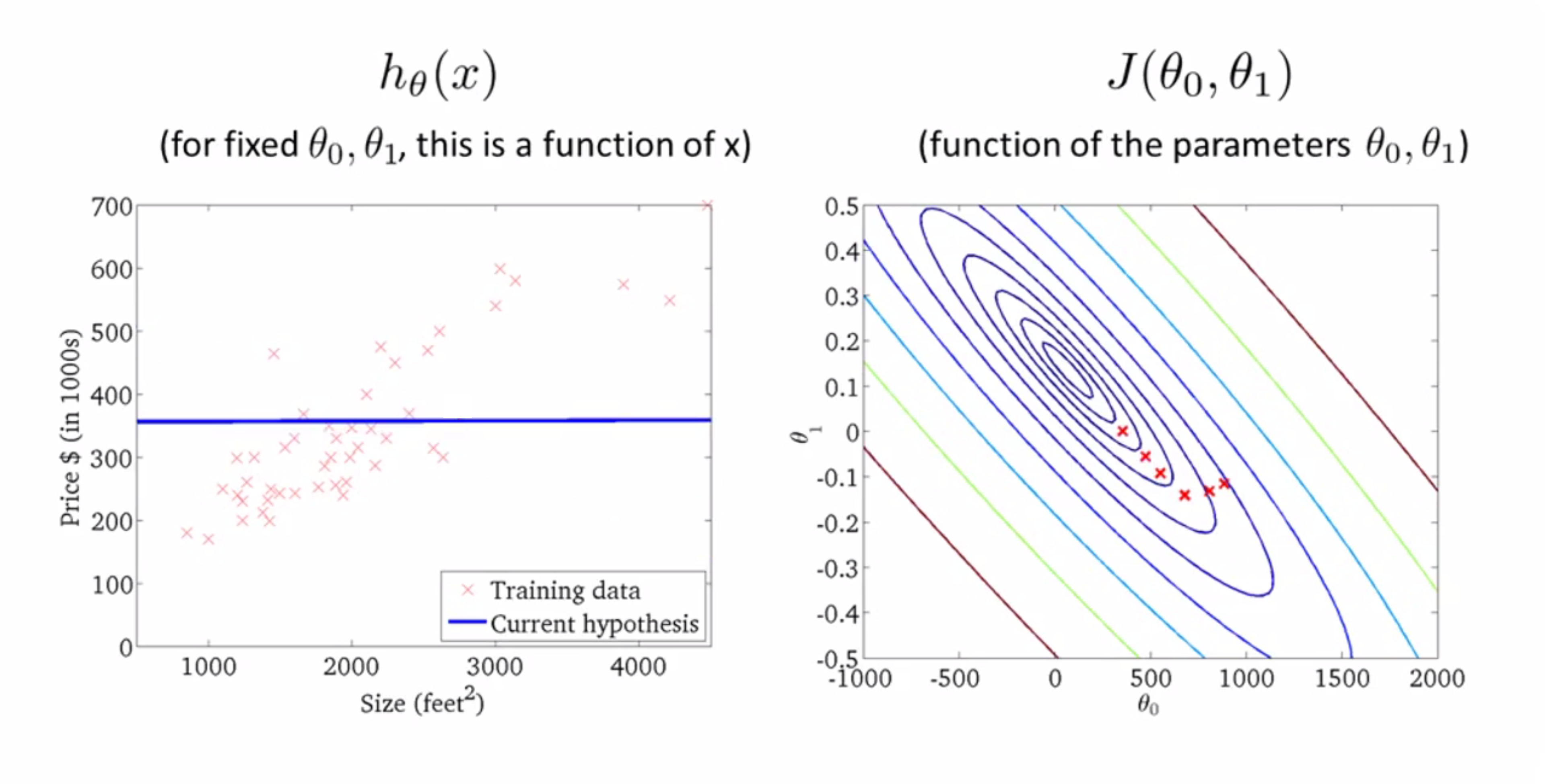
再来一步:
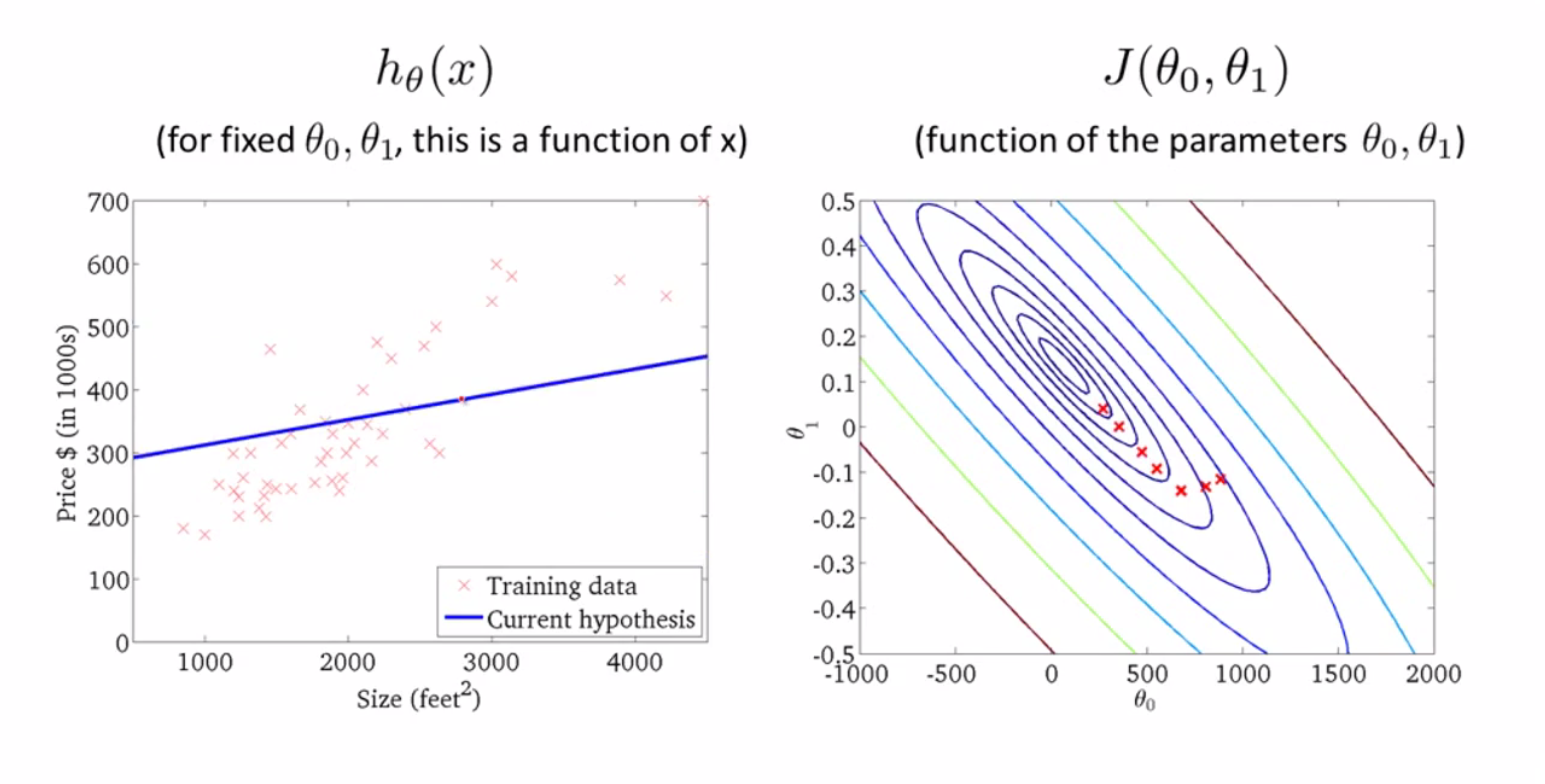
再来一步:
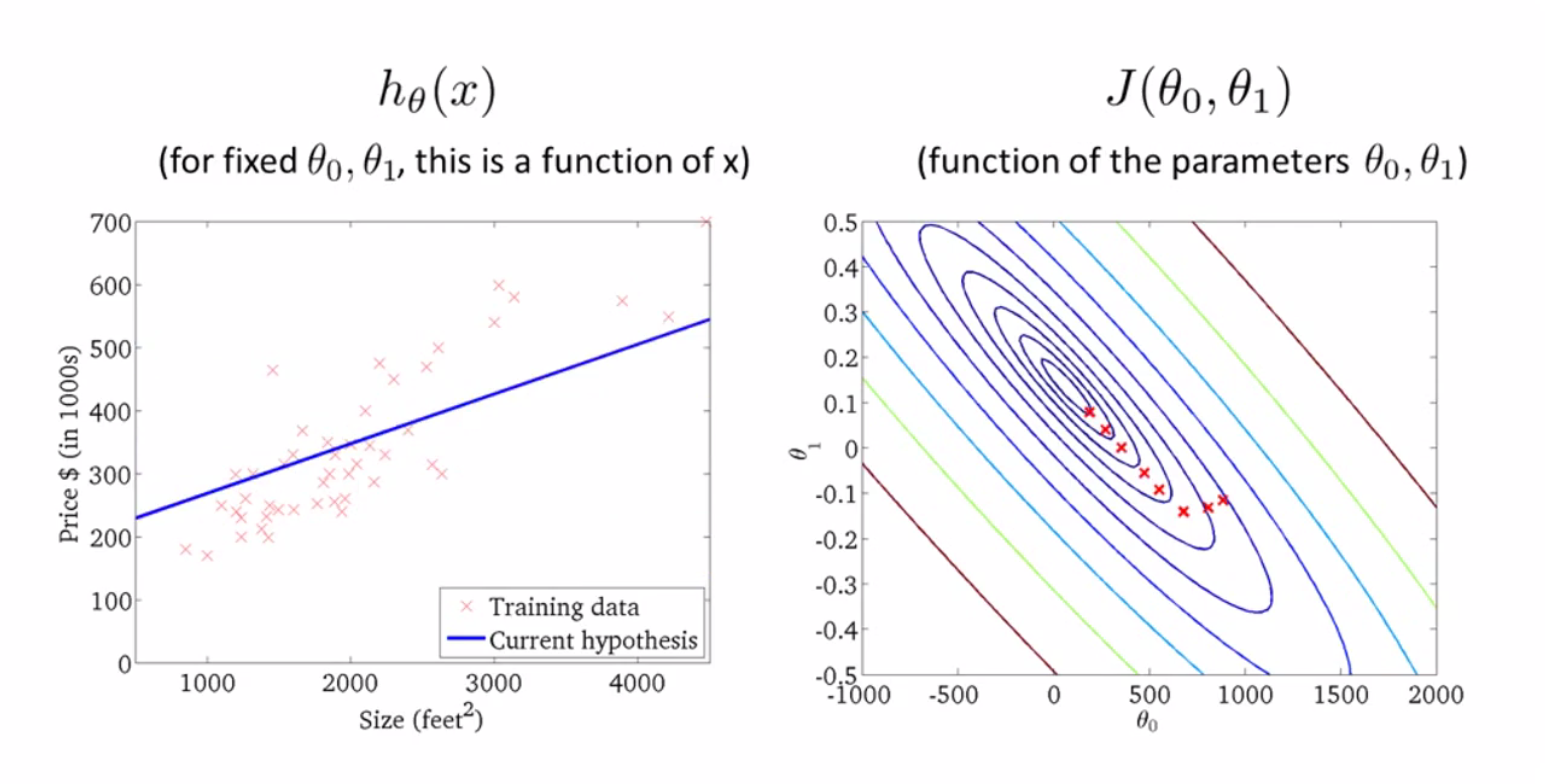
最后来一步:
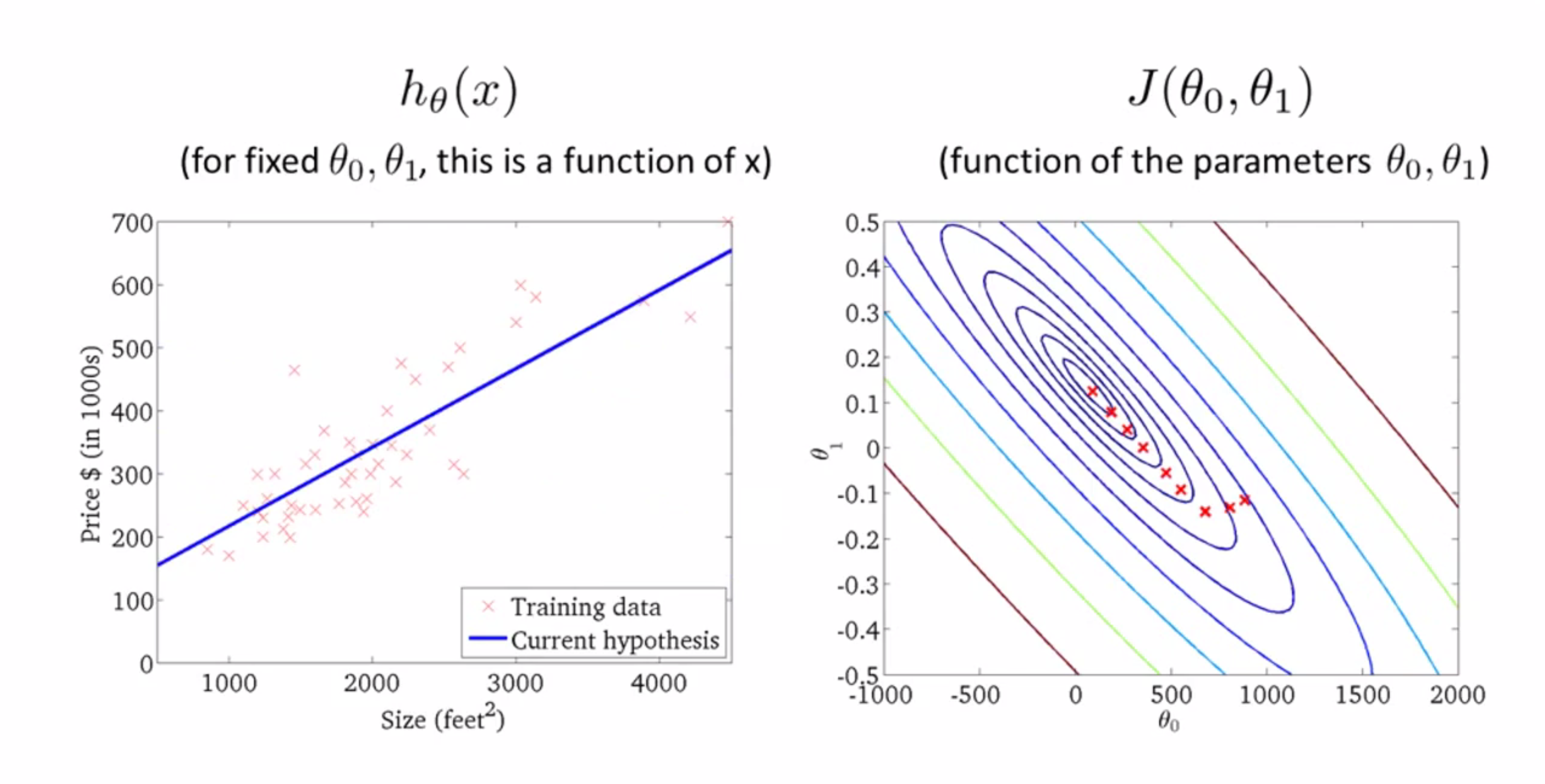
然后我们发现到达了局部最优解的点,算法也就结束了。这时如果你朋友有套房子,面积1250平方英尺,你现在可以读出值并告诉他这大概能卖25万美元的房子:
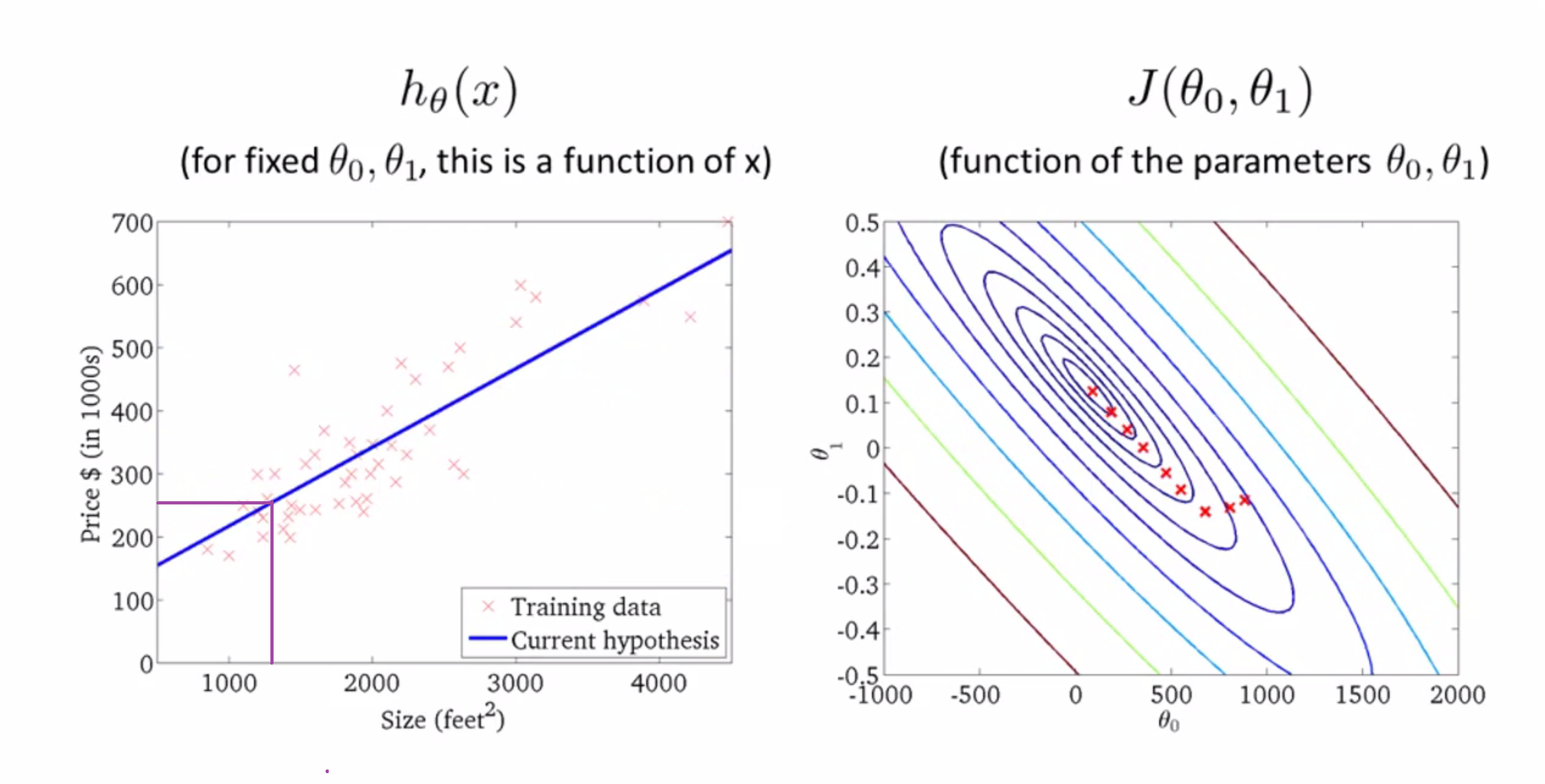
顺带一提,在机器学习中我们有个叫“批梯度”(batch)的词,指的是在梯度下降的每一步,我们都会用上所有的数据(我们用了Σ)。
其实在线性代数中,存在着最小费用的数值解法和法方程法,都可以不用梯度下降来解决这类回归问题。但梯度下降法能更好地适应大数据量,在现实运用中往往比那个法方程方法更精确。
算法实现
思路在上面已经很清楚的介绍了,下面给我自己用CPP实现的代码,供大家交流学习:
#include <cmath>
#include <cstdio>
#include <cstdlib>
#include <cstring>
#include <algorithm>
using namespace std;
int n;
double ans0, ans1;
double x[11000], y[11000];
const double Alpha = 3 * 1e-1;
void read() {
printf("请输入样本大小:\n");
scanf("%d", &n);
printf("请依次输入房子大小x和售价y:\n");
for(int i = 1; i <= n; i++) {
scanf("%lf %lf", &x[i], &y[i]);
}
return;
}
void work() {
ans0 = 0.0; ans1 = 0.0;
double delta = 1;
int m;
printf("请输入下降次数:\n");
scanf("%d", &m);
for(int o = 1; o <= m; o++) {
double temp0 = ans0, temp1 = ans1;
for(int i = 1; i <= n; i++) {
temp0 = temp0 - (Alpha / (double)m) * (ans0 + ans1 * x[i] - y[i]);
temp1 = temp1 - (Alpha / (double)m) * (ans0 + ans1 * x[i] - y[i]) * x[i];
}
ans0 = temp0;
ans1 = temp1;
}
return ;
}
void write() {
printf("拟合出的直线为:");
if(ans1 > 0)printf("y = %0.1lf + %0.1lf * x\n", ans0, ans1);
else printf("y = %0.1lf - %0.1lf * x\n", ans0, -ans1);
}
int main() {
read();
work();
write();
return 0;
} 其效果还是不错的:
结语
通过这篇BLOG,相信你也已经学会了人生中的第一个机器学习算法——梯度下降算法,其实梯度下降算法不仅在解决J函数,在解决某些其他凸函数的最值时也有很大的应用空间,快去实践一下吧!最后希望你喜欢这篇BLOG!


你说的好