在之前的几篇BLOG中,我们一同学习了很多关于神经网络的零散的知识。下面就让我们一同把它们整合起来。
网络结构选择
当我们准备训练一个神经网络时,我们要做的第一件事就是搭建网络的大体框架,这里我说的框架指的是神经元之间的连接模式。比如我们可能会从以下几种结构中选择:

上图中,第一种神经网络的结构是一个输入层三个输入单元,一个隐藏层五个隐藏单元和一个输出层四个输出单元;第二种结构是一个输入层三个输入单元作为输入层,两层隐藏层每层五个隐藏单元,一个输出层四个输出单元;第三种是一个输入层三个输入单元作为输入层,三层隐藏层每层五个隐藏单元,一个输出层四个输出单元。
我们所要取舍的,只是每一层的隐藏单元数量以及隐藏层的数量。因为单元的数量是由我们样本的特征集确定的,而输出层的单元数目又是由我们所要区分的类别个数确定的。值得提醒的是,假如在多元分类问题中 y 的取值范围是在 1 到 10 之间,即我们有 10 个可能的分类,假如最后的分类结果是第五类,那么在我们的神经网络的输出中,输出的就不是单纯的数值 5 ,而是一个向量[0 0 0 0 1 0 0 0 0 ]。
而对于隐藏单元的个数以及隐藏层的数目,我们一般都有一个默认的规则,那就是只使用单个隐藏层,一般来说是最普遍适用的。但如果我们一定要使用不止一个隐藏层的话,同样我们也有一个默认规则,那就是每一个隐藏层通常都有相同的单元数。虽然通常情况下隐藏单元越多越好,但是我们需要注意的是,如果有大量隐藏单元,计算量一般会比较大。 并且一般来说隐藏单元每层神经元的数目和输入特征的数量相同或者是它的二倍三倍四倍之类的,一般来说隐藏单元的数目取为稍大于输入特征数目都是可以接受的。
前向传播和反向传播
下面我们来总结一下如何实现神经网络的训练过程,其实一共有六个步骤,下面我们来一一道来。
第一步,选择神经网络结构构建一个神经网络,然后随机初始化权值。通常我们把权值初始化为很小的值,一般接近于零。
第二步,执行前向传播算法,对于该神经网络的任意一个输入 x(i),计算出对应的 h(x) 值,即一个输出值 y 向量。
第三步,通过代码计算出代价函数J(θ)。
第四步,执行反向传播算法,来算出这些偏导数项,即 J(θ) 关于参数 θ 的偏微分。具体来说我们要对所有训练集数据使用一个for循环进行遍历:
for i = 1:m
Perform forward propagation and'backpropagation using example (x(i), y(i));
(Get activations a(l) and delta terms δ(l) for L = 2, 3 …… L).可能你之前听说过一些比较先进的分解方法,可能不需要像这里一样使用 for 循环来对所有 m 个训练样本进行遍历。 但是这是你第一次进行反向传播算法,所以我建议你最好还是使用一个for循环来完成程序,我们对每一个训练样本进行迭代,从x(1) y(1)开始对第一个样本进行前向传播运算和反向传播运算,然后在第二次循环中同样地对第二个样本执行前向传播和反向传播算法……以此类推直到最后一个样本。
第五步,使用梯度检查。比较这些已经计算得到的偏导数项 与用数值方法得到的估计值,确保两种方法得到基本接近的两个值,以确保我们的反向传播算法得到的结果是正确的。但必须要说明的一点是,我们检查完后需要去掉梯度检查的代码,因为梯度检查的计算非常慢。
第六步,使用一个最优化算法比如说梯度下降算法或者说是更加高级的优化方法,比如说BFGS算法、共轭梯度法或者其他一些已经内置到fminunc函数中的方法,将所有这些优化方法和反向传播算法相结合来最小化关于代价函数 J(θ) 的函数值。
另外顺便提一下,对于神经网络代价函数 J(θ) 是一个非凸函数,因此理论上是只能够停留在局部最小值的位置。实际上梯度下降算法和其他一些高级优化方法一样理论上只能保证是收敛于局部最小值,不一定是全局最小值。但一般来讲 这个问题其实并不是什么要紧的事,通常能够我们的算法都得到一个很小的局部最小值。尽管这可能不一定是全局最优值。
最后梯度下降算法似乎对于神经网络来说还是比较神秘,希望下面这幅图能让你对梯度下降法在神经网络中的应用产生一个更直观的理解:
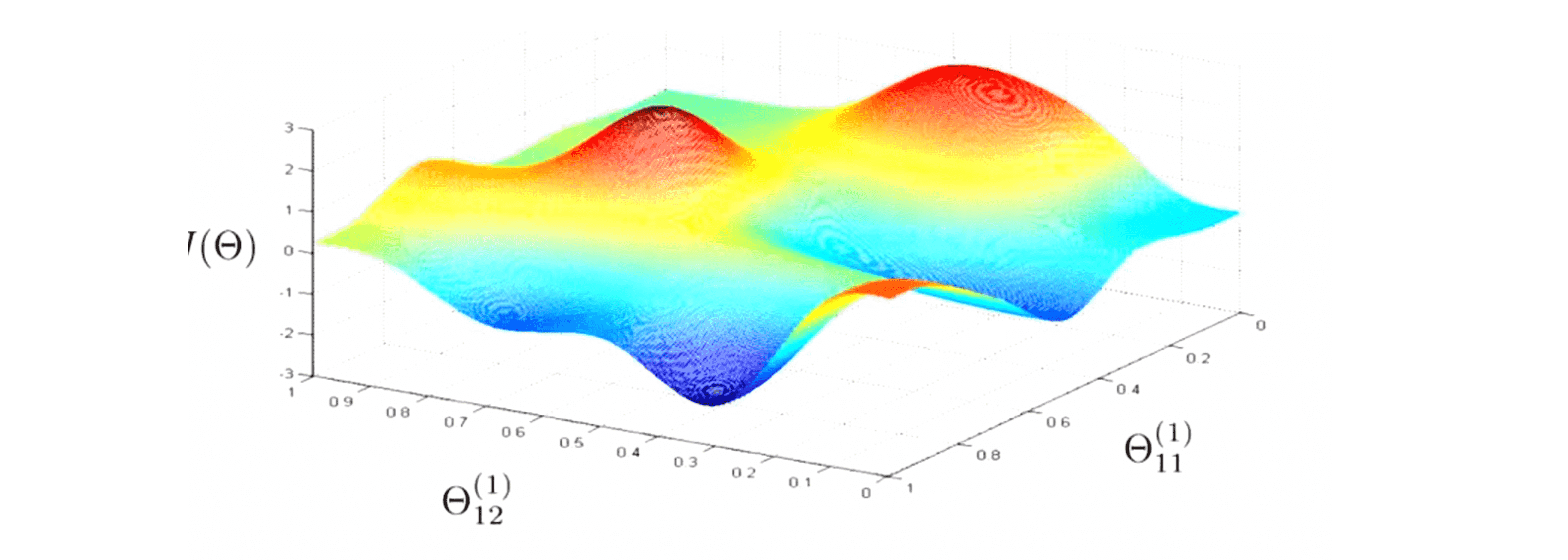
这实际上有点类似我们早先时候解释梯度下降时的思路,我们有某个代价函数并且在我们的神经网络中有一系列参数值。,这里我只写下了两个参数。那么代价函数 J(θ) 度量的就是这个神经网络对训练数据的拟合情况,所以如果你取某个参数比如最下面这点,在这个点上 J(θ) 的值是非常小的。对于大部分的训练集数据,通过神经网络后,我们的代价函数 J(θ) 的值都是非常小的,即我的假设函数的输出会非常接近于y(i)。因此梯度下降算法的原理是我们从某个随机的初始点开始,不停地向局部最低点往下下降,而反向传播算法的目的就是算出梯度下降的方向,而梯度下降的过程 就是沿着这个方向一点点的下降,一直到我们希望得到的点,即局部最优点。所以当我们在执行反向传播算法并且使用梯度下降或者更高级的优化方法时,这幅图片很好地帮我们解释其基本的原理。
前沿应用
在之前的BLOG中,我们举了神经网络的一个应用就是去识别手写字母,接下来让我们再来看看另一个应用——就是实现自动驾驶。下面我们就来看看 Dean Pomerleau——卡耐基梅隆大学教授的成果。
在这个实验中,这位教授将神经网络的结果可视化了:
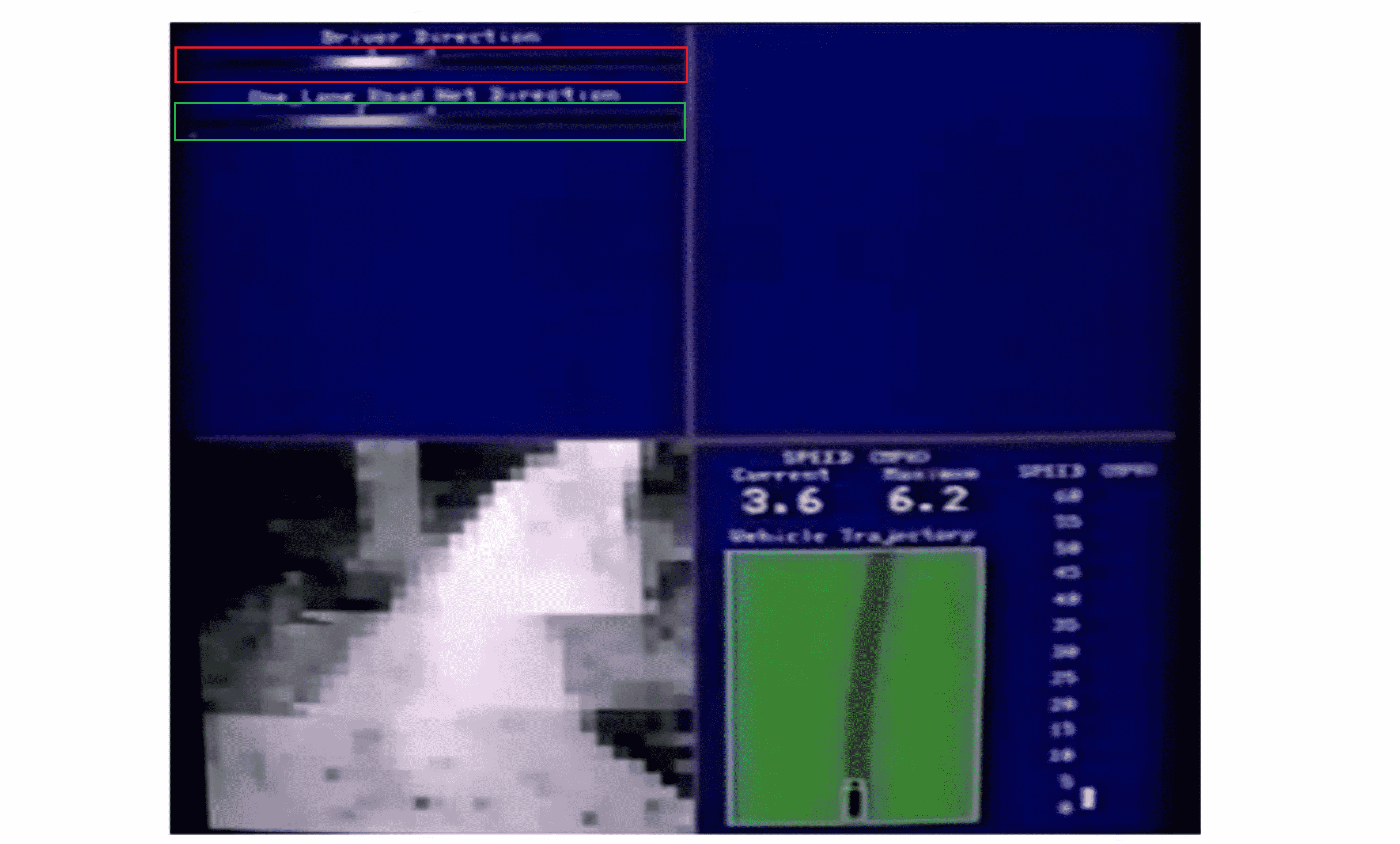
左上方的红色框框就是驾驶员的判断结果,白色的亮斑代表的是左转还是右转之类的,下面的绿色框框这是我们机器学习的成果。下面的左方是汽车所看到的前方的路况图像,右边则是一些其他的参数,下面我们来看这个具体的例子。
ALVINN (Autonomous Land Vehicle In a Neural Network) 是一个基于神经网络的智能系统通过观察人类的驾驶来学习驾驶的智能系统。刚开始时,我们的机器判断时均称的灰色区域,这代表着神经网络已经随机初始化了,并且初始化时我们并不知道汽车如何行驶:
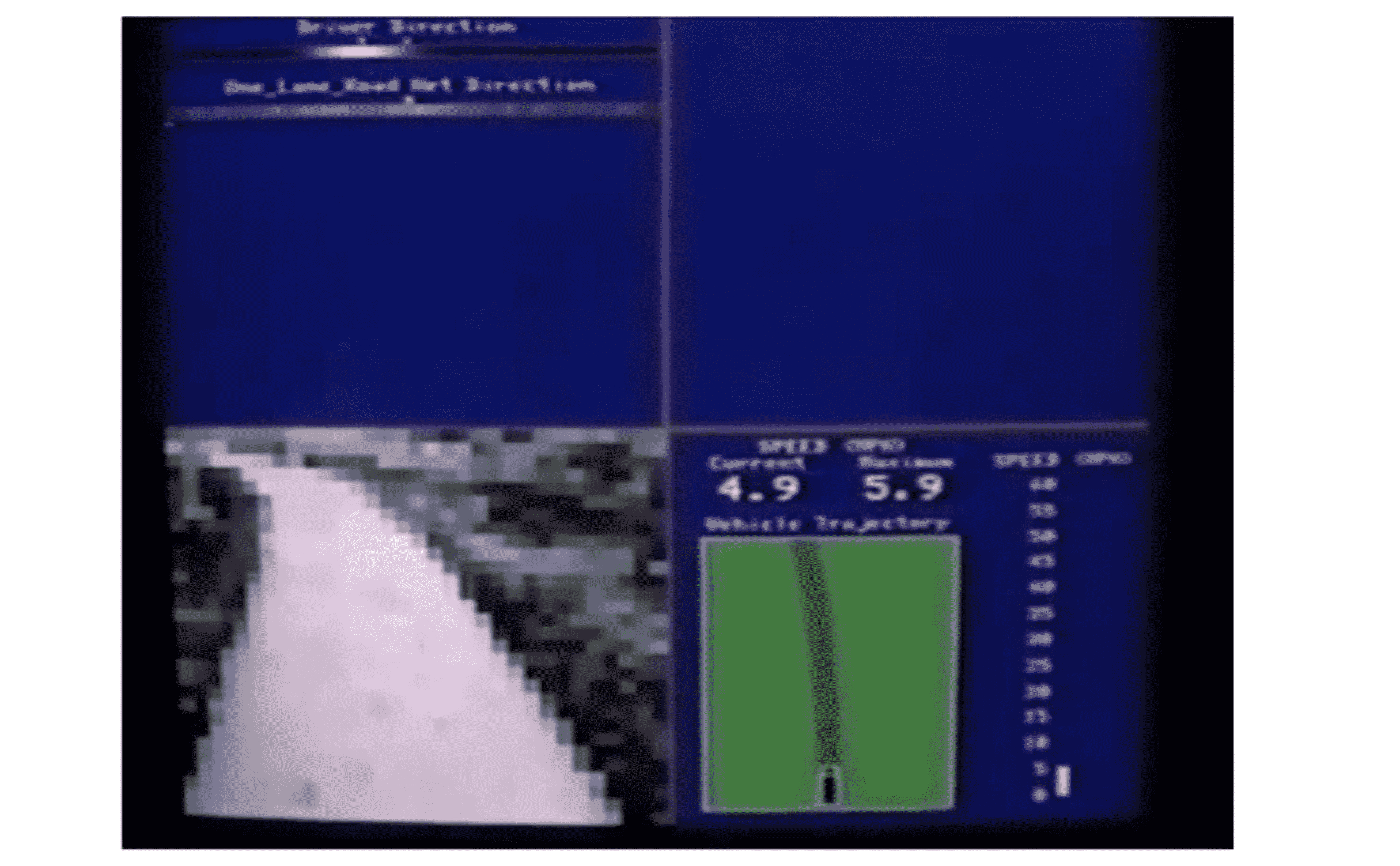
当学习算法运行了一段时间之后,它逐渐明白了人类的判断机制,才渐渐出现了一条白色的区段,显示出一个具体的行驶方向,这就表示神经网络算法在这时候已经选出了一个明确的行驶方向:

随着时间的推进,机器预测的白色越来越明显,代表它对结果的自信程度越来越大:
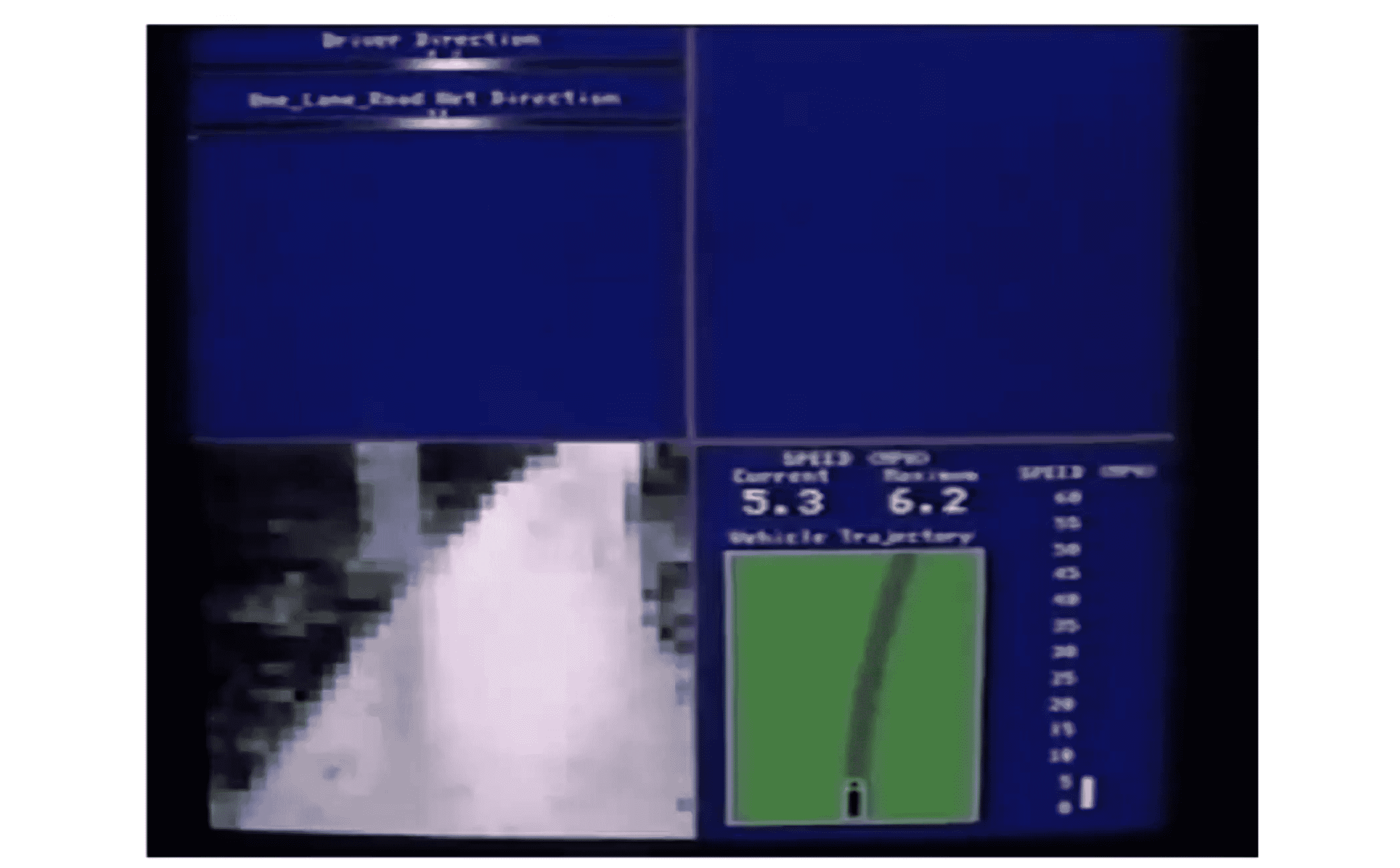
到十分钟左右,机器的预测就已经和人类相差无几了:

通过上面这个例子,我们看到神经网络在机器学习中的巨大用途,也看到了这个算法实现的高效性和可靠性。
结语
通过这篇BLOG,相信你已经全面掌握了神经网络算法。在后续的BLOG里,我们会结合实例进行实现。最后希望你喜欢这篇BLOG!

